Achieving Sub-Millisecond Proxy Overhead



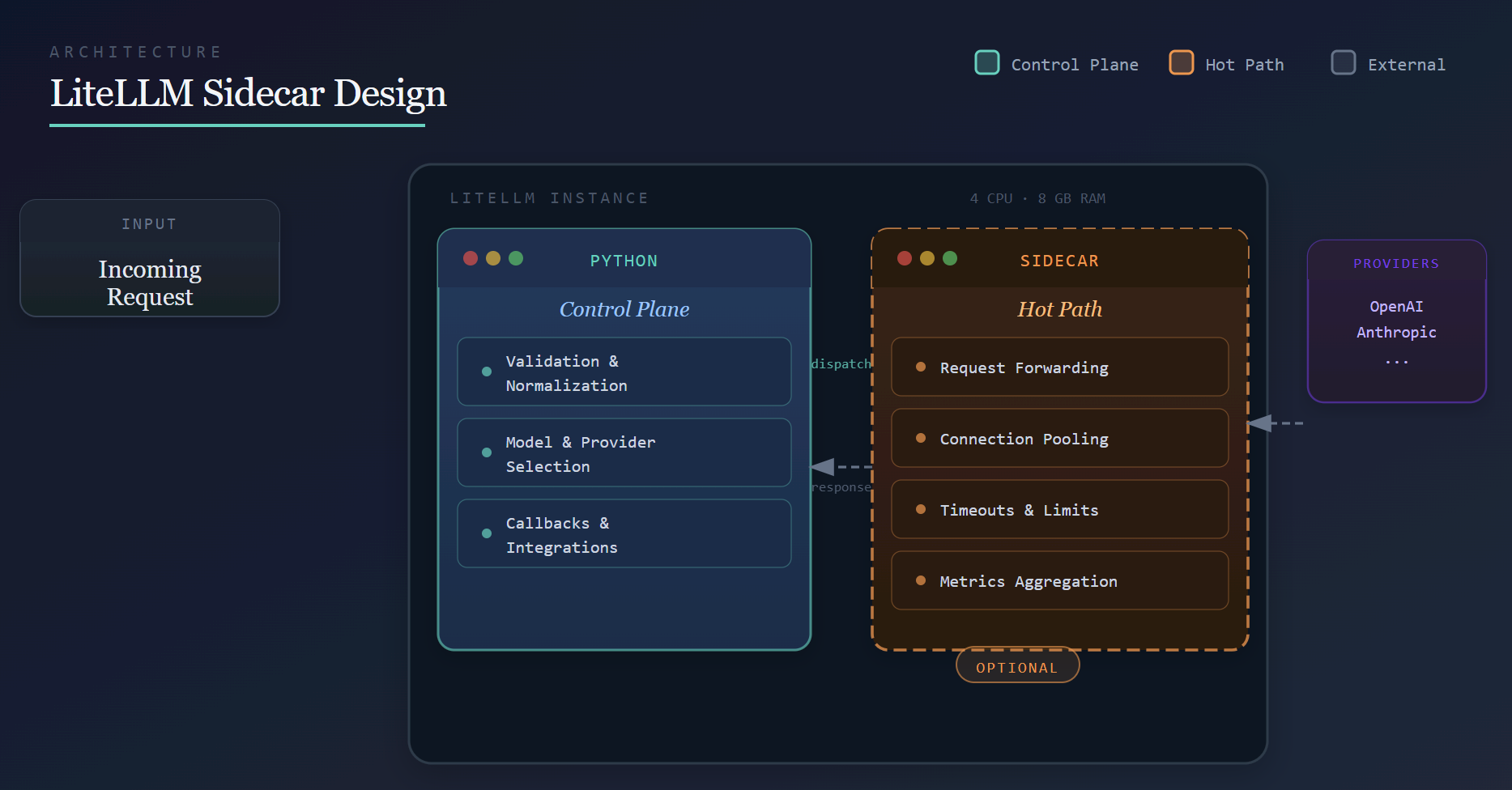
Introduction
Our Q1 performance target is to aggressively move toward sub-millisecond proxy overhead on a single instance with 4 CPUs and 8 GB of RAM, and to continue pushing that boundary over time. Our broader goal is to make LiteLLM inexpensive to deploy, lightweight, and fast. This post outlines the architectural direction behind that effort.
Proxy overhead refers to the latency introduced by LiteLLM itself, independent of the upstream provider.
To measure it, we run the same workload directly against the provider and through LiteLLM at identical QPS (for example, 1,000 QPS) and compare the latency delta. To reduce noise, the load generator, LiteLLM, and a mock LLM endpoint all run on the same machine, ensuring the difference reflects proxy overhead rather than network latency.