Over the last two weeks we addressed two major product quality issues:
The MCP Gateway did not have a single class for credential resolution.
Pass-through APIs had high memory consumption.
Across the same window we shipped 134 bug fixes in total. This post covers the two big changes first, then the rest of the AI Eng and reliability work, the full breakdown, and what we are doing next.
Over the past year, we have heard the same thing from our users and our community: they want the fastest, most lightweight AI gateway they can run. We have heard you. We are addressing it by moving LiteLLM to Rust, and committing to sub-1ms overhead with a sub-100MB memory binary you can deploy. By the end of this migration, you will get a pure Rust server that can serve 100% of your AI traffic, with every hot path operation, including auth and rate limiting, running in Rust.
Want to help us build it?
We are opening an early beta and want to work directly with teams who care about a fast, lightweight gateway. If that is you, sign up here and we will get you testing the Rust gateway in your own stack, with a direct line to our team.
The reason it matters: under real load, CPU and memory climb with concurrency, and pods get OOM-killed at the worst time. Today the LiteLLM Python proxy peaks around 359MB of memory under load, and that cost multiplies across every pod, region, and retry you run.
We are already seeing the payoff in benchmarks. The Rust gateway serves about 15x the throughput (453 to 6,782 requests per second) on about 11x less memory (359MB to 32MB), and cuts per-request overhead from about 7.5ms on the Python path to about 0.05ms, well under the 1ms we commit to.
You deploy a single Rust binary. It uses about 65MB of memory, gateway overhead stays under 1ms, and nothing in your setup changes: same config.yaml, same database, same client API, same providers. You keep LiteLLM's coverage of 100+ LLM providers behind one OpenAI-compatible API, with /chat/completions, /messages, /responses, and every other LLM endpoint LiteLLM supports today, now as the fastest and most lightweight LLM gateway you can self-host.
This is not a v2 and not a rewrite. There is no new major version to migrate to and nothing for you to change. The runtime under the hot path gets faster and lighter while your config stays exactly where it is.
We ship this the careful way. Each route moves to Rust only after it passes our full parity and end-to-end test suite, and it runs in production before the next route starts. Stability is the priority, and we target zero regressions on every release.
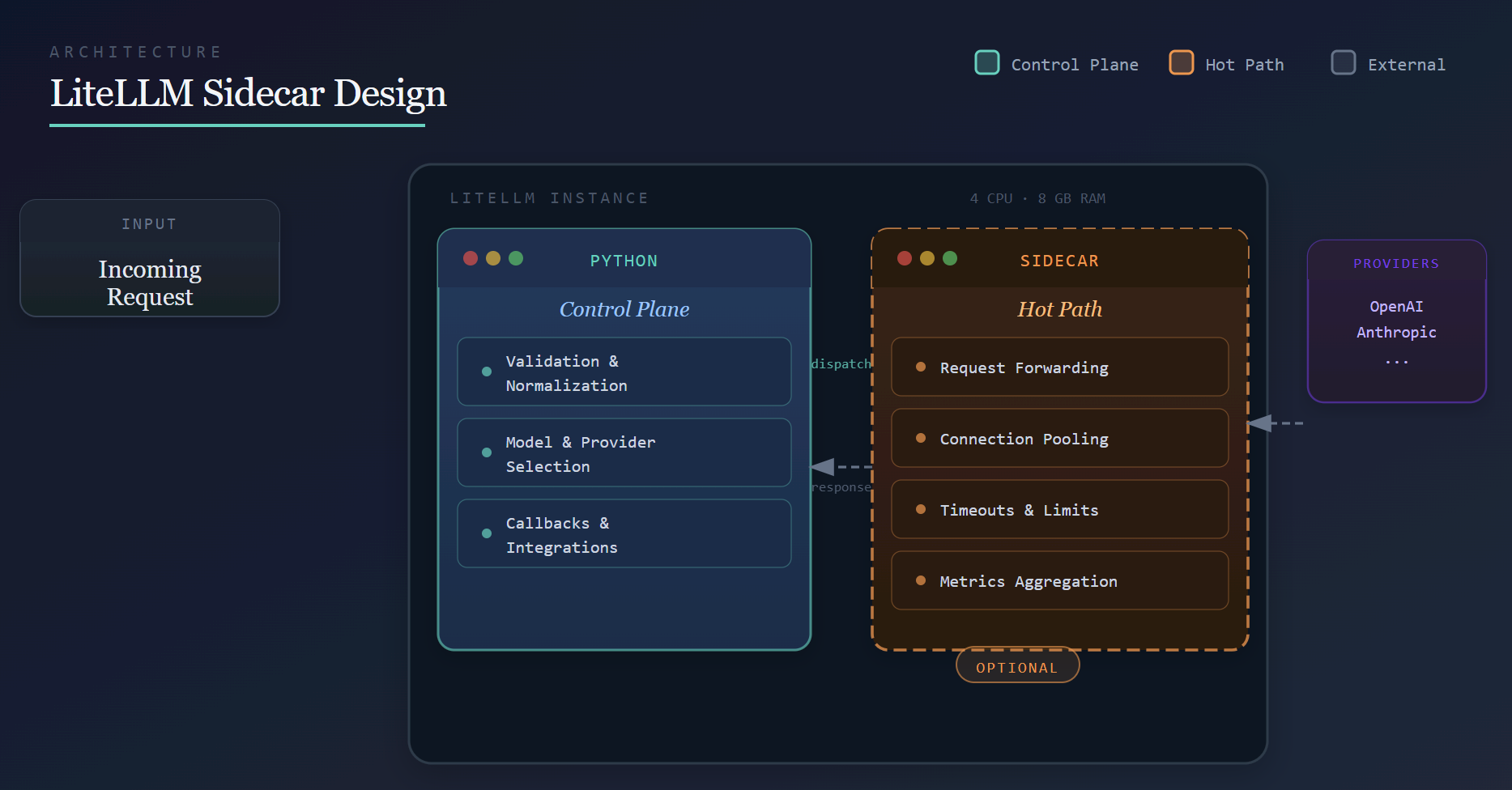
The LiteLLM proxy container does 2 very different things. It's an LLM data plane, /chat/completions, /v1/messages, embeddings, passthroughs, where latency is measured in single-digit milliseconds of overhead and traffic is high-volume and bursty. It's also a management control plane — keys, teams, SSO, audit logs, and the spend/usage analytics that power the dashboard, where a single request can scan millions of rows.
Run both on the same event loop, and the slowest thing the control plane does sets the reliability floor for the fastest thing the data plane does. This post is about how we've improved LiteLLM's reliability at scale by offering a componentized deployment model.
The LiteLLM proxy server has two middleware layers. The first is Starlette's CORSMiddleware (re-exported by FastAPI), which is a pure ASGI middleware. Then we have a simple BaseHTTPMiddleware called PrometheusAuthMiddleware.
The job of PrometheusAuthMiddleware is to authenticate requests to the /metrics endpoint. It's not on by default, you enable it with a flag in your proxy config:
The middleware checks two things: is the request hitting /metrics, and is auth even enabled? If both checks fail, which they do for the vast majority of requests, it just passes the request through unchanged.
Our Q1 performance target is to aggressively move toward sub-millisecond proxy overhead on a single instance with 4 CPUs and 8 GB of RAM, and to continue pushing that boundary over time. Our broader goal is to make LiteLLM inexpensive to deploy, lightweight, and fast. This post outlines the architectural direction behind that effort.
Proxy overhead refers to the latency introduced by LiteLLM itself, independent of the upstream provider.
To measure it, we run the same workload directly against the provider and through LiteLLM at identical QPS (for example, 1,000 QPS) and compare the latency delta. To reduce noise, the load generator, LiteLLM, and a mock LLM endpoint all run on the same machine, ensuring the difference reflects proxy overhead rather than network latency.