OpenTelemetry v1
OpenTelemetry is a CNCF standard for observability. It connects to any observability tool, such as Jaeger, Zipkin, Datadog, New Relic, Traceloop, Levo AI and others.
There's a newer, opt-in OpenTelemetry v2 integration for LiteLLM Proxy that produces one trace per request (HTTP → auth → guardrails → LLM call → DB writes), follows the official GenAI semantic conventions, and ships with presets for Arize, Phoenix, Langfuse, Weave, and more. Enable it with LITELLM_OTEL_V2=true.
From v1.81.0, the request/response is set as attributes on the parent Received Proxy Server Request span by default — there is no separate litellm_request span unless you opt in. To restore nested litellm_request spans, set USE_OTEL_LITELLM_REQUEST_SPAN=true. See Span Hierarchy for the full picture and Why don't I see a litellm_request span? for when to flip the flag.
Getting Started
Install the OpenTelemetry SDK:
uv add opentelemetry-api opentelemetry-sdk opentelemetry-exporter-otlp
Set the environment variables (different providers may require different variables):
- Log to Traceloop Cloud
- Log to OTEL HTTP Collector
- Log to OTEL GRPC Collector
- Log to Laminar
- Splunk Observability Cloud
OTEL_EXPORTER="otlp_http"
OTEL_ENDPOINT="https://api.traceloop.com"
OTEL_HEADERS="Authorization=Bearer%20<your-api-key>"
OTEL_EXPORTER_OTLP_ENDPOINT="http://0.0.0.0:4318"
OTEL_EXPORTER_OTLP_PROTOCOL=http/json
OTEL_EXPORTER_OTLP_HEADERS="api-key=key,other-config-value=value"
OTEL_EXPORTER_OTLP_ENDPOINT="http://0.0.0.0:4318"
OTEL_EXPORTER_OTLP_PROTOCOL=grpc
OTEL_EXPORTER_OTLP_HEADERS="api-key=key,other-config-value=value"
Note: OTLP gRPC requires
grpcio. Install viauv add "litellm[grpc]"(orgrpcio).
OTEL_EXPORTER="otlp_grpc"
OTEL_ENDPOINT="https://api.lmnr.ai:8443"
OTEL_HEADERS="authorization=Bearer <project-api-key>"
Note: OTLP gRPC requires
grpcio. Install viauv add "litellm[grpc]"(orgrpcio).
OTEL_EXPORTER_OTLP_ENDPOINT="https://ingest.<realm>.observability.splunkcloud.com/v2/trace/otlp"
OTEL_EXPORTER_OTLP_PROTOCOL=http/protobuf
OTEL_EXPORTER_OTLP_HEADERS="X-SF-Token=<your-ingest-access-token>"
OTEL_SERVICE_NAME="litellm-proxy"
For LiteLLM Proxy setup, ingest token patterns, and trace verification, see Splunk Observability Cloud (OpenTelemetry).
Use just 1 line of code, to instantly log your LLM responses across all providers with OpenTelemetry:
litellm.callbacks = ["otel"]
Span Hierarchy
Every LLM request handled by the LiteLLM Proxy produces a tree of spans rooted at Received Proxy Server Request. Conditional spans below are only emitted when their controlling flag is set or their feature is in use.
Received Proxy Server Request (SpanKind.SERVER, root)
│
├── litellm_request (INTERNAL, only when USE_OTEL_LITELLM_REQUEST_SPAN=true)
│ ├── raw_gen_ai_request (INTERNAL — provider request/response, content-capture-gated)
│ └── guardrail (INTERNAL — one per executed guardrail)
│
├── raw_gen_ai_request (INTERNAL — when litellm_request is collapsed into the root)
├── guardrail (INTERNAL — when litellm_request is collapsed into the root)
│
├── auth, router, self, proxy_pre_call, (INTERNAL — service-hook spans, see below)
│ redis, postgres, batch_write_to_db
│
└── Failed Proxy Server Request (INTERNAL — only on exception)
In semconv mode (OTEL_SEMCONV_STABILITY_OPT_IN=gen_ai_latest_experimental), when an LLM-call span is created its name becomes {operation} {model} (e.g. chat gpt-4) with SpanKind.CLIENT, and raw_gen_ai_request is suppressed. The same USE_OTEL_LITELLM_REQUEST_SPAN gating decides whether the span is emitted at all. See Opt-In to Latest GenAI Semantic Conventions.
The SDK (no proxy) emits litellm_request as the root if no parent context exists — there is no Received Proxy Server Request span in pure-SDK use.
Span name reference
| Span name | Span kind | Parent | When emitted |
|---|---|---|---|
Received Proxy Server Request | SERVER | root (or external traceparent if present) | Once per HTTP request to the LiteLLM Proxy |
litellm_request | INTERNAL | proxy root (proxy) or root (SDK) | When USE_OTEL_LITELLM_REQUEST_SPAN=true (proxy) or no parent context exists (SDK). In semconv mode replaced by {operation} {model} |
raw_gen_ai_request | INTERNAL | litellm_request if present, else proxy root | One per upstream provider call. Carries provider-native request/response under llm.{provider}.*. Suppressed in semconv mode and when message content capture is disabled |
guardrail | INTERNAL (OpenInference kind = guardrail) | litellm_request if present, else proxy root | One span per guardrail execution (pre-call, during-call, or post-call) |
Failed Proxy Server Request | INTERNAL | proxy root | When the proxy raises an exception before completing the request |
{route} (e.g. /user/info, /key/info) | INTERNAL | proxy root | Management-endpoint calls (non-LLM proxy routes) |
auth, router, self, proxy_pre_call, redis, postgres, batch_write_to_db, reset_budget_job, pod_lock_manager | INTERNAL | proxy root | Service-hook spans — see below |
Service-hook spans (a.k.a. "infrastructure" spans)
LiteLLM has a separate hook (async_service_success_hook / async_service_failure_hook) that records timing for internal subsystems like the router, auth checks, Redis, Postgres, and the proxy pre-call pipeline. When the OTEL integration is active and a parent span is in context, each of these hooks creates an INTERNAL child span.
The span name is the ServiceTypes enum value (auth, router, self, proxy_pre_call, redis, postgres, …). The full set is defined in litellm/types/services.py. self is the LiteLLM SDK itself (e.g. timing of make_openai_chat_completion_request); router may appear multiple times per request (once for async_get_available_deployment, once for the wrapping acompletion).
Each service-hook span carries:
| Attribute | Value |
|---|---|
service | The service enum value (e.g. "router", "redis") |
call_type | The specific operation (e.g. "async_get_available_deployment", "acompletion", "add_litellm_data_to_request") |
error | Set on failure spans only |
| (custom event_metadata) | Whatever the caller attached |
These spans are operational/infrastructure spans, not GenAI semantic spans. They are useful for SRE-level debugging (where is time being spent inside LiteLLM?) but they do not carry gen_ai.* attributes. If you only want AI-semantic spans in your backend, filter on the presence of gen_ai.system (or on span name).
There is currently no env var that disables individual service-hook spans. If you need them filtered, do it at the OTLP collector / backend layer (e.g. via a tail-based sampler that drops by name).
Why don't I see a litellm_request span?
Behavior changed in v1.81.0. By default, USE_OTEL_LITELLM_REQUEST_SPAN=false and the proxy collapses the litellm_request span into the parent Received Proxy Server Request span — its gen_ai.* attributes are set on the parent instead. This:
- Avoids duplicating attributes across parent and child.
- Reduces span count (and storage cost) by ~1 span per request.
- Keeps the trace shallow when a parent context already exists.
To restore the older nested behavior — where every LLM call gets its own litellm_request span as a child of the proxy root span — set:
USE_OTEL_LITELLM_REQUEST_SPAN=true
This is the right setting if:
- One HTTP request makes multiple
litellm.completioncalls — under the default behavior the last call's attributes overwrite earlier ones on the shared parent. - You want a clean parent for
raw_gen_ai_requestandguardrailchildren that is not the HTTP request span. - Your backend's UI is built around AI-semantic span names like
litellm_request.
This is not a regression; the change is intentional. The flag is read fresh on every request, so it can be flipped without restarting.
In semconv mode (OTEL_SEMCONV_STABILITY_OPT_IN=gen_ai_latest_experimental), the same USE_OTEL_LITELLM_REQUEST_SPAN gating still decides whether the LLM-call span is emitted; semconv mode only changes the span's name (to {operation} {model}), kind (to CLIENT), and child structure.
Context propagation (W3C traceparent)
LiteLLM honors the W3C Trace Context header. If your client (or upstream gateway) sends a traceparent header, LiteLLM creates the Received Proxy Server Request span as a child of that external trace, so LiteLLM's spans appear inline inside whatever distributed trace your application already has.
Parent-context resolution order (highest priority first):
- Explicit
litellm_parent_otel_spanin the requestmetadata. - Inbound
traceparentHTTP header (extracted viaTraceContextTextMapPropagator). - The currently-active span in the OTEL global context (thread-local).
- None — LiteLLM's span is the root.
To force every LiteLLM trace to be its own root regardless of inbound headers or active context, set OTEL_IGNORE_CONTEXT_PROPAGATION=true.
Running Multiple OpenTelemetry Handlers
You can run more than one OpenTelemetry handler in the same process, for example a generic OTLP exporter alongside a backend-specific subclass. Set skip_set_global=True on every handler past the first so each one gets its own private TracerProvider, MeterProvider, and LoggerProvider. Spans, metrics, and log events then flow only through that handler's exporter.
import litellm
from litellm.integrations.opentelemetry import OpenTelemetry, OpenTelemetryConfig
# Primary handler. Claims the global TracerProvider.
primary = OpenTelemetry(config=OpenTelemetryConfig(
exporter="otlp_http",
endpoint="https://your-collector/v1/traces",
))
# Secondary handler. Has its own private providers.
secondary = OpenTelemetry(config=OpenTelemetryConfig(
exporter="otlp_http",
endpoint="https://second-collector/v1/traces",
skip_set_global=True,
))
litellm.callbacks = [primary, secondary]
Init order does not matter. Both handlers receive their own spans regardless of which is constructed first.
Cross-collector behavior (e.g. LangSmith + generic OTEL)
When two OTEL-emitting integrations are active at once — for instance a customized LangSmith OTEL handler plus the generic otel exporter — both honor the same traceparent propagation rules and the same parent-resolution order described in Context propagation. As long as one handler uses skip_set_global=True, both will:
- See the same
trace_idfor a given request. - Emit the same span hierarchy (
Received Proxy Server Request→litellm_requestif enabled →raw_gen_ai_request/guardrail). - Differ only in which exporter they ship spans to.
If a customized LangSmith OTEL handler is configured to mount litellm_request only when the request carries a traceparent (otherwise no-op), the generic OTEL handler still emits its full hierarchy. The two views remain readable independently because the span names and attributes are identical.
Capturing Message Content
LiteLLM uses the standard OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT environment variable to control whether prompts and completions are captured, and where:
# Do not capture message content
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=NO_CONTENT
# Capture content on span attributes only
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=SPAN_ONLY
# Capture content on event attributes only
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=EVENT_ONLY
# Capture content on both spans and events
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=SPAN_AND_EVENT
A boolean form is also accepted: true maps to EVENT_ONLY, false maps to NO_CONTENT.
Per-handler content policy
When running multiple OpenTelemetry handlers, set capture_message_content on each OpenTelemetryConfig so the handlers can have different content policies. For example, send full prompts to a debugging backend while stripping content from a compliance-focused OTLP collector:
import litellm
from litellm.integrations.opentelemetry import OpenTelemetry, OpenTelemetryConfig
stripped = OpenTelemetry(config=OpenTelemetryConfig(
exporter="otlp_http",
endpoint="https://compliance-collector/v1/traces",
capture_message_content="NO_CONTENT",
))
verbose = OpenTelemetry(config=OpenTelemetryConfig(
exporter="otlp_http",
endpoint="https://debug-collector/v1/traces",
capture_message_content="SPAN_AND_EVENT",
skip_set_global=True,
))
litellm.callbacks = [stripped, verbose]
Resolution order (highest priority first):
litellm.turn_off_message_logging=TrueforcesNO_CONTENT(dynamic kill-switch; overrides everything below).OpenTelemetryConfig.capture_message_content(per-handler field, sampled at handler init).OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENTenv var (sampled at handler init).- The legacy per-instance
message_loggingflag — defaults toTrue, which maps toSPAN_AND_EVENT.
Opt-In to Latest GenAI Semantic Conventions
Set OTEL_SEMCONV_STABILITY_OPT_IN=gen_ai_latest_experimental to emit spans that follow the latest OpenTelemetry GenAI semantic conventions:
OTEL_SEMCONV_STABILITY_OPT_IN=gen_ai_latest_experimental
This changes the LLM-call span name, kind, and structure, suppresses the non-standard raw_gen_ai_request child span, adds the gen_ai.provider.name attribute alongside gen_ai.system, populates additional request and cache-token attributes when present, and consolidates the per-message events into a single gen_ai.client.inference.operation.details event. See the Spans Reference and Attributes Reference below for the per-row differences.
OpenTelemetryConfig.semconv_stability is the programmatic equivalent. The flag is comma-separable per the OTEL spec.
Redacting Messages, Response Content from OpenTelemetry Logging
Redact Messages and Responses from all OpenTelemetry Logging
Set litellm.turn_off_message_logging=True This will prevent the messages and responses from being logged to OpenTelemetry, but request metadata will still be logged.
Redact Messages and Responses from specific OpenTelemetry Logging
In the metadata typically passed for text completion or embedding calls you can set specific keys to mask the messages and responses for this call.
Setting mask_input to True will mask the input from being logged for this call
Setting mask_output to True will make the output from being logged for this call.
Be aware that if you are continuing an existing trace, and you set update_trace_keys to include either input or output and you set the corresponding mask_input or mask_output, then that trace will have its existing input and/or output replaced with a redacted message.
Troubleshooting
I don't see a litellm_request span
Expected behavior under the v1.81.0+ default (USE_OTEL_LITELLM_REQUEST_SPAN=false): the proxy root span absorbs the LLM-call attributes and there is no separate litellm_request span. To restore nested spans, set USE_OTEL_LITELLM_REQUEST_SPAN=true. See Why don't I see a litellm_request span?.
If you're in semconv mode, the LLM-call span exists but is renamed to {operation} {model} (e.g. chat gpt-4) — search by gen_ai.system rather than by the literal name litellm_request.
I only see infrastructure spans (router, auth, redis, proxy_pre_call)
Those are service-hook spans. They're emitted alongside the AI-semantic spans (raw_gen_ai_request, guardrail, and litellm_request if enabled), not instead of them. If you genuinely don't see any gen_ai.* attributes anywhere in your trace:
- Verify
litellm.callbacks(orlitellm_settings.callbacks) includes"otel". - Verify the request actually hit a
/chat/completions(or other LLM) route — management endpoints (/key/info,/user/info, …) won't havegen_ai.*attributes. - Check whether
litellm.turn_off_message_logging=trueand/ormask_input/mask_outputare set — they suppress message and raw-provider attributes. - Set
USE_OTEL_LITELLM_REQUEST_SPAN=trueso the LLM attributes land on a span namedlitellm_requestinstead of being co-mingled with HTTP request attributes onReceived Proxy Server Request.
Trace LiteLLM Proxy user/key/org/team information on failed requests
LiteLLM emits metadata.user_api_key_* attributes (key hash, key alias, org ID, user ID, team ID) on both successful and failed requests. They appear on the litellm_request span when present, otherwise on Received Proxy Server Request.
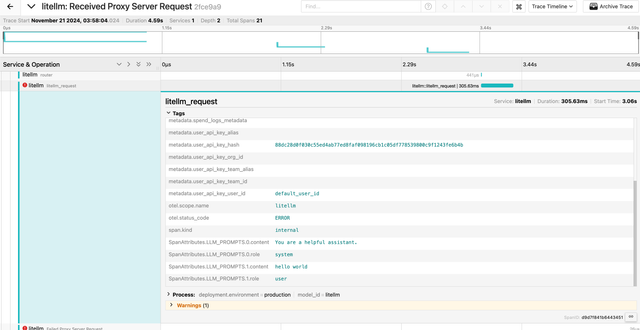
Not seeing traces land on Integration
If you don't see traces landing on your integration, set OTEL_DEBUG="True" in your LiteLLM environment and try again.
export OTEL_DEBUG="True"
This will emit any logging issues to the console. Common causes:
OTEL_EXPORTER_OTLP_ENDPOINTpoints to an HTTPS endpoint but the protocol isgrpc(or vice-versa).OTEL_HEADERSis missing the auth header your backend expects.- A firewall/sidecar is dropping outbound OTLP traffic on 4317/4318.
- For gRPC,
grpcioisn't installed (uv add "litellm[grpc]").
Spans are getting truncated or dropped
OTLP exporters batch spans. Very large gen_ai.input.messages/gen_ai.output.messages (e.g. multi-megabyte prompts) can exceed default OTLP attribute size limits at the collector. Either:
- Move large payloads off-trace (set
litellm.turn_off_message_logging=trueand rely on Spend Logs / cold storage, referenced viametadata.cold_storage_object_key). - Raise the collector's
max_attribute_value_lengthand OTLP receivermax_recv_msg_size_mib.
Control metric attribute cardinality
When metrics are enabled, every gen_ai.client.* sample is stamped with a common set of attributes so you can slice the histograms by model, provider, key, and team. By default that set also includes per-request fields such as hidden_params and several metadata.* values. Those are close to unique per request, so each one multiplies the number of time series the backend tracks (one series per distinct attribute combination). At volume this explodes metric cardinality, and some backends, for example Splunk Observability Cloud, start throttling or dropping the metrics.
To cap cardinality, filter which attributes get stamped onto metrics. Nest an attributes block under callback_settings.otel with either an include_list (allowlist; emit only the listed attributes) or an exclude_list (denylist; emit everything except the listed attributes). The two are mutually exclusive, and setting both raises a configuration error at startup. With no attributes block the behavior is unchanged and every attribute is emitted, so existing dashboards keep working.
The filter applies to metrics only. Spans keep their full attribute set, so traces stay rich while metric cardinality stays bounded.
Drop the high-cardinality attributes (exclude_list)
The common case. Keep the stable identity attributes and drop the per-request blobs that drive cardinality.
litellm_settings:
callbacks: ["otel"]
callback_settings:
otel:
attributes:
exclude_list:
- hidden_params
- metadata.requester_metadata
- metadata.requester_ip_address
- metadata.spend_logs_metadata
- metadata.mcp_tool_call_metadata
- metadata.vector_store_request_metadata
- metadata.prompt_management_metadata
Emit only an explicit set (include_list)
When you want the smallest, most predictable attribute set, list exactly the attributes to keep. Anything not listed is dropped from metrics.
litellm_settings:
callbacks: ["otel"]
callback_settings:
otel:
attributes:
include_list:
- gen_ai.operation.name
- gen_ai.system
- gen_ai.request.model
- gen_ai.framework
- metadata.user_api_key_team_id
- metadata.user_api_key_org_id
gen_ai.token.type cannot be filtered. It is a structural discriminator stamped onto the input and output token series after filtering so the two stay distinct, and listing it in either include_list or exclude_list is rejected at startup rather than silently ignored.
Valid attribute names
Both lists are validated at startup against the set below. An unknown name raises a configuration error, so a typo can never silently fall back to emitting every attribute. The valid names are the gen_ai.* core attributes, hidden_params, and the metadata.* keys:
gen_ai.operation.namegen_ai.systemgen_ai.request.modelgen_ai.frameworkhidden_paramsmetadata.user_api_key_hashmetadata.user_api_key_aliasmetadata.user_api_key_team_idmetadata.user_api_key_org_idmetadata.user_api_key_user_idmetadata.user_api_key_team_aliasmetadata.user_api_key_user_emailmetadata.user_api_key_end_user_idmetadata.spend_logs_metadatametadata.requester_ip_addressmetadata.requester_metadatametadata.prompt_management_metadatametadata.applied_guardrailsmetadata.mcp_tool_call_metadatametadata.vector_store_request_metadata
Configuration Reference
All flags below are read from environment variables unless noted. Boolean flags accept true/false (case-insensitive).
Exporter & resource
| Variable | Default | Purpose |
|---|---|---|
OTEL_EXPORTER (alias: OTEL_EXPORTER_OTLP_PROTOCOL) | console | Exporter type. Common values: console, otlp_http, otlp_grpc, http/json, http/protobuf, grpc |
OTEL_ENDPOINT (alias: OTEL_EXPORTER_OTLP_ENDPOINT) | none | OTLP endpoint URL |
OTEL_HEADERS (alias: OTEL_EXPORTER_OTLP_HEADERS) | none | Comma-separated key=value,key2=value2 header list |
OTEL_SERVICE_NAME | litellm | Resource attribute service.name |
OTEL_ENVIRONMENT_NAME | production | Resource attribute deployment.environment |
OTEL_MODEL_ID | OTEL_SERVICE_NAME | Resource attribute model_id |
OTEL_TRACER_NAME | litellm | Tracer name |
LITELLM_METER_NAME | litellm | Meter name (when metrics enabled) |
LITELLM_LOGGER_NAME | litellm | Logger name (when events enabled) |
OTEL_LOGS_EXPORTER | none | Logs exporter (e.g. console) when events are enabled |
Span / metric / event toggles
| Variable | Default | Effect |
|---|---|---|
USE_OTEL_LITELLM_REQUEST_SPAN | false | Force litellm_request to always be emitted as a child of the proxy root span. See Why don't I see a litellm_request span? |
OTEL_SEMCONV_STABILITY_OPT_IN | unset | Set to gen_ai_latest_experimental to switch to the latest GenAI semantic conventions. Comma-separable per OTEL spec |
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT | unset → falls back to legacy message_logging (default True → SPAN_AND_EVENT) | NO_CONTENT / SPAN_ONLY / EVENT_ONLY / SPAN_AND_EVENT. Boolean form accepted (true→EVENT_ONLY, false→NO_CONTENT) |
LITELLM_OTEL_INTEGRATION_ENABLE_METRICS | false | Enable OTLP metrics (TTFT, TPOT, response duration, cost, token usage, operation duration) |
LITELLM_OTEL_INTEGRATION_ENABLE_EVENTS | false | Enable OTLP semantic logs (gen_ai.content.prompt/gen_ai.content.completion, or gen_ai.client.inference.operation.details in semconv mode) |
OTEL_IGNORE_CONTEXT_PROPAGATION | false | If true, ignore inbound traceparent headers and any active span — every LiteLLM trace becomes its own root |
OTEL_DEBUG / DEBUG_OTEL | false | Print exporter and span-creation diagnostics to stderr |
litellm.turn_off_message_logging (Python global / litellm_settings.turn_off_message_logging) | false | Kill-switch for content capture. Suppresses llm.{provider}.* raw request/response, gen_ai.input.messages, gen_ai.output.messages, and gen_ai.content.* log events. Overrides per-handler capture_message_content |
Per-request redaction (request metadata)
Per-request keys you can pass in metadata to redact a single call without disabling logging globally.
| Key | Effect |
|---|---|
mask_input | When true, redacts the input messages on this request |
mask_output | When true, redacts the output messages on this request |
update_trace_keys | Controls which trace keys (input, output) get replaced when continuing an existing trace |
generation_name | Overrides the raw_gen_ai_request span's name with this value |
OpenTelemetryConfig programmatic equivalents
| Field | Default | Purpose |
|---|---|---|
exporter | console | Same as OTEL_EXPORTER |
endpoint | none | Same as OTEL_ENDPOINT |
headers | none | Same as OTEL_HEADERS |
enable_metrics | false | Same as LITELLM_OTEL_INTEGRATION_ENABLE_METRICS |
enable_events | false | Same as LITELLM_OTEL_INTEGRATION_ENABLE_EVENTS |
capture_message_content | env var | Per-handler override; same value space as OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT |
semconv_stability | env var | Same as OTEL_SEMCONV_STABILITY_OPT_IN |
skip_set_global | false | Don't claim the process-global TracerProvider/MeterProvider/LoggerProvider |
ignore_context_propagation | false | Same as OTEL_IGNORE_CONTEXT_PROPAGATION |
attributes | none | Metric attribute include/exclude filter. See Control metric attribute cardinality |
Appendix: Spans, Metrics, and Attributes Reference
This appendix enumerates every span, metric, and AI-semantic attribute LiteLLM emits, including how each changes when semconv mode is enabled.
Spans Reference
The LLM-call span is the AI-semantic core. Its name, kind, and supporting child spans depend on whether semconv mode is active.
| Span | Kind | Default mode | Semconv mode |
|---|---|---|---|
| Proxy request frame | SERVER | Received Proxy Server Request | Received Proxy Server Request (unchanged) |
| LLM-call span | INTERNAL (default) / CLIENT (semconv) | litellm_request (only when USE_OTEL_LITELLM_REQUEST_SPAN=true; otherwise attributes land on the proxy frame span) | {operation} {model} (e.g. chat gpt-4, embeddings text-embedding-3-small); same USE_OTEL_LITELLM_REQUEST_SPAN gating as default mode |
| Raw provider payload | INTERNAL | raw_gen_ai_request (when message content capture is permitted) | not emitted (data lives on the LLM-call span and the consolidated event) |
| Guardrail check | INTERNAL | one span per guardrail invocation, named per guardrail | unchanged |
| Management endpoint | INTERNAL | one span per proxy admin call, named per endpoint | unchanged |
Operation names emitted in semconv mode: chat (default), embeddings (when call type contains embedding), text_completion (when call type contains text_completion).
Events Reference
Events land on the LiteLLM-managed LoggerProvider when enable_events=True on the config.
| Event | Default mode | Semconv mode |
|---|---|---|
| Per-message prompt | gen_ai.content.prompt (one event per input message) | replaced by the consolidated event |
| Per-choice completion | gen_ai.content.completion (one event per choice) | replaced by the consolidated event |
| Consolidated inference details | not emitted | gen_ai.client.inference.operation.details (one event per call, carrying gen_ai.input.messages and gen_ai.output.messages arrays per the spec) |
Metrics Reference
LiteLLM emits the following histograms when enable_metrics=True is set on the OpenTelemetryConfig. Metric names match the OTEL GenAI semantic conventions.
| Metric | Unit | Description |
|---|---|---|
gen_ai.client.operation.duration | s | End-to-end operation duration including LiteLLM overhead. |
gen_ai.client.token.usage | {token} | Token usage. Records two histograms per call (label gen_ai.token.type is "input" or "output"). |
gen_ai.client.token.cost | USD | Computed request cost. |
gen_ai.client.response.time_to_first_token | s | Time from request start to first streamed token (streaming requests only). |
gen_ai.client.response.time_per_output_token | s | Average time per output token (generation time / completion tokens). |
gen_ai.client.response.duration | s | LLM API generation time, excluding LiteLLM overhead. |
Common labels on every histogram: gen_ai.operation.name, gen_ai.system, gen_ai.request.model, gen_ai.framework="litellm".
| Common metric ask | Metric |
|---|---|
| TTFT | gen_ai.client.response.time_to_first_token |
| TPS | derived as 1 / gen_ai.client.response.time_per_output_token |
| Token usage | gen_ai.client.token.usage (split by gen_ai.token.type) |
| Vendor/model latency (excludes overhead) | gen_ai.client.response.duration |
| Vendor/model latency (includes overhead) | gen_ai.client.operation.duration |
Spans → Derived Metrics
Even with metrics off, every metric below can be derived from spans. This is what most dashboards do.
| Metric | How to derive from spans |
|---|---|
| TTFT (Time to First Token) | Streaming requests only. Use the dedicated gen_ai.client.response.time_to_first_token metric, or capture completion_start_time from request kwargs via a custom callback. |
| TPOT (Time per Output Token) | Use the gen_ai.client.response.time_per_output_token metric, or derive as gen_ai.client.response.duration ÷ gen_ai.usage.output_tokens. |
| Total response duration | gen_ai.client.response.duration metric, or end_time − start_time of the LLM-call span (or proxy root span minus LiteLLM overhead — see hidden_params.litellm_overhead_time_ms). |
| Vendor (provider) latency | Duration of the raw_gen_ai_request span (default mode) — pure time spent waiting on the upstream provider. In semconv mode, use gen_ai.client.response.duration. |
| LiteLLM overhead | hidden_params.litellm_overhead_time_ms on the proxy root span. Or Received Proxy Server Request.duration − raw_gen_ai_request.duration. |
| Token usage | gen_ai.usage.input_tokens, gen_ai.usage.output_tokens, gen_ai.usage.total_tokens on the LLM span (or gen_ai.client.token.usage metric). |
| Cost | gen_ai.cost.total_cost (and the rest of gen_ai.cost.*) on the LLM span; or gen_ai.client.token.cost metric. |
| Guardrail evaluation time | Duration of each guardrail span. Disambiguate by guardrail_name and guardrail_mode. |
| Router / auth / Redis / DB latency | Duration of the corresponding service-hook span (router, auth, redis, postgres, …). |
| Retry / fallback count | hidden_params.x-litellm-attempted-retries and hidden_params.x-litellm-attempted-fallbacks on the proxy root span. |
| Streaming? | llm.is_streaming attribute ("True"/"False"). |
Attributes Reference
Attributes set on the LLM-call span. Names follow OTEL GenAI semconv.
| Attribute | Default mode | Semconv mode |
|---|---|---|
gen_ai.operation.name | the litellm call_type (e.g. acompletion) | the semconv operation (chat, embeddings, text_completion) |
gen_ai.system | provider name (e.g. openai) | unchanged |
gen_ai.provider.name | not set | provider name (the renamed Required attribute per spec) |
gen_ai.framework | litellm | litellm |
gen_ai.request.model | model | model |
gen_ai.request.max_tokens, temperature, top_p | when set in the request | when set in the request |
gen_ai.request.frequency_penalty, presence_penalty, top_k, seed, stop_sequences, stream, choice.count | not set | when set in the request |
gen_ai.response.model, gen_ai.response.id, gen_ai.response.finish_reasons | when present in the response | unchanged |
gen_ai.usage.input_tokens, gen_ai.usage.output_tokens, gen_ai.usage.total_tokens | when present | unchanged |
gen_ai.usage.cache_creation.input_tokens, gen_ai.usage.cache_read.input_tokens | not set | when present in the response |
gen_ai.input.messages, gen_ai.output.messages, gen_ai.system_instructions | when message content capture permits, JSON-encoded array of {role, parts: [...]} objects | unchanged |
gen_ai.cost.input_cost, output_cost, total_cost (and related cost breakdown attrs) | LiteLLM-specific cost attributes | unchanged |
gen_ai.cost.* (cost breakdown, all modes)
LiteLLM expands every key from standard_logging_payload["cost_breakdown"] as gen_ai.cost.{key}. Currently observed keys:
| Attribute | Meaning |
|---|---|
gen_ai.cost.input_cost | Prompt token cost (USD) |
gen_ai.cost.output_cost | Completion token cost (USD) |
gen_ai.cost.total_cost | Charged total (USD) |
gen_ai.cost.tool_usage_cost | Cost attributable to tool/function calls |
gen_ai.cost.original_cost | Pre-discount cost |
gen_ai.cost.discount_percent, gen_ai.cost.discount_amount | Discount applied |
gen_ai.cost.margin_percent, gen_ai.cost.margin_fixed_amount, gen_ai.cost.margin_total_amount | Margin components |
litellm.* (proxy root and LLM span)
| Attribute | Value |
|---|---|
litellm.call_id | Unique per litellm.completion invocation. Use this to correlate trace data with LiteLLM Spend Logs and the LiteLLM UI |
litellm.request.type | Same as call_type (e.g. acompletion, aembedding, aimage_generation) |
llm.* (proxy root and LLM span)
| Attribute | Value |
|---|---|
llm.request.type | LiteLLM call_type |
llm.is_streaming | "True" or "False" |
llm.user | user parameter, if set |
llm.{provider}.* (raw provider request/response, default mode only)
Set only on raw_gen_ai_request, to avoid attribute duplication. For each key in the raw provider request body, LiteLLM emits llm.{provider}.{key}. Same for the raw response body.
Examples observed for openai:
llm.openai.messages
llm.openai.model
llm.openai.temperature
llm.openai.max_tokens
llm.openai.id
llm.openai.object
llm.openai.created
llm.openai.choices
llm.openai.usage
llm.openai.system_fingerprint
llm.openai.service_tier
llm.openai.extra_body
For Anthropic, replace openai with anthropic (llm.anthropic.messages, llm.anthropic.stop_reason, etc.). Same pattern for every other provider.
These attributes are suppressed when OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=NO_CONTENT, when litellm.turn_off_message_logging=true, or in semconv mode (where the entire raw_gen_ai_request span is suppressed).
metadata.* (proxy root, sometimes LLM span)
LiteLLM iterates standard_logging_payload["metadata"] and emits each entry as metadata.{key}. Common keys (not exhaustive):
| Attribute | Meaning |
|---|---|
metadata.user_api_key_hash | SHA hash of the virtual key used |
metadata.user_api_key_alias | Virtual-key alias |
metadata.user_api_key_team_id, metadata.user_api_key_team_alias | Team identifiers |
metadata.user_api_key_org_id, metadata.user_api_key_org_alias | Organization identifiers |
metadata.user_api_key_user_id, metadata.user_api_key_user_email | LiteLLM internal user identifiers |
metadata.user_api_key_end_user_id | End-user passed in request |
metadata.user_api_key_project_id, metadata.user_api_key_project_alias | Project identifiers |
metadata.user_api_key_spend, metadata.user_api_key_max_budget, metadata.user_api_key_budget_reset_at | Budget state |
metadata.user_api_key_request_route | Route hit (e.g. /v1/chat/completions) |
metadata.requester_ip_address, metadata.user_agent | Client identifiers |
metadata.requester_metadata, metadata.requester_custom_headers | Headers and request context |
metadata.applied_guardrails | List of guardrails that ran on this request |
metadata.mcp_tool_call_metadata, metadata.vector_store_request_metadata | MCP and vector-store request info |
metadata.usage_object | Full token-usage object |
metadata.spend_logs_metadata | Custom metadata persisted to Spend Logs |
metadata.cold_storage_object_key | When request payloads are offloaded to cold storage |
metadata.user_api_key_auth_metadata | Extra auth context |
Plus hidden_params — a single attribute holding a JSON-serialized dict that includes litellm_overhead_time_ms, api_base, response_cost, additional_headers, model_id, x-litellm-attempted-retries, x-litellm-attempted-fallbacks, etc.
Guardrail span attributes
Set on each guardrail child span:
| Attribute | Value |
|---|---|
openinference.span.kind | "guardrail" (per OpenInference convention) |
guardrail_name | E.g. "presidio-pii", "lakera", "aporia" |
guardrail_mode | "pre_call", "during_call", "post_call", etc. |
masked_entity_count | If the guardrail masked entities |
guardrail_response | The guardrail's response/action |
The span's start_time/end_time come from the guardrail's own timing, so the span duration equals the guardrail evaluation time.
There is no separate guardrail_pre/guardrail_post span name today — both are emitted as guardrail and disambiguated via the guardrail_mode attribute.
Service-hook span attributes
See Service-hook spans. Each carries service, call_type, optional error, plus any custom event metadata the caller attached.
Exception attributes
On Failed Proxy Server Request (and on any LLM-call span on failure):
| Attribute | Value |
|---|---|
exception | str(original_exception) |
| Span status | StatusCode.ERROR |
Resource attributes (every span)
| Attribute | Default | Override |
|---|---|---|
service.name | litellm | OTEL_SERVICE_NAME |
deployment.environment | production | OTEL_ENVIRONMENT_NAME |
model_id | matches service.name | OTEL_MODEL_ID |
telemetry.sdk.{language,name,version} | set by SDK | — |
Stability
Span names, metric names, and the attribute set above are stable across LiteLLM patch releases. The LLM-call span name and kind change between Default mode and Semconv mode and migrate via the documented opt-in flag rather than between releases.
Support
For LiteLLM OTEL integration questions, file an issue at BerriAI/litellm. For OpenLLMetry / Traceloop semantic-convention questions, see Slack or email dev@traceloop.com.