✨ Enterprise
- New to Enterprise? Start with the ✨ Enterprise Quickstart
- Free trial: 30-day enterprise license
- Talk to us: Book a demo
- SSO is free for up to 5 users. Beyond that, an enterprise license is required.
Who is Enterprise for?
For teams running LiteLLM at scale — 100+ users or 10+ production AI use-cases — that need SSO, audit logs, fine-grained access control, and professional support on top of OSS. Not sure if you qualify? Get in touch.
Why Enterprise?
LiteLLM OSS already covers the fundamentals — an OpenAI-compatible gateway, virtual keys, spend tracking, budgets, fallbacks, and request/response logging. Enterprise adds the controls larger organizations need to safely give hundreds of users and dozens of applications access to LLMs.
| OSS | Enterprise | |
|---|---|---|
| Auth | API keys | SSO + SCIM, OIDC/JWT |
| Key Management | Virtual keys, users, teams across LLM APIs, MCPs, and Agents | Organizations, org/team admins, delegated admin roles |
| Security | — | Key rotations, read/write to secret manager |
| Guardrails | Always-on / request-based1 | Key and team scoped guardrails |
| Logging | Request/response logging, Prometheus metrics | Per-key / per-team routing to Langfuse, Langsmith, Arize and more. Management-op logs |
| Deployment | Single-region proxy | Multi-region deployment under one license, admin/worker split |
1 The OSS guardrail framework supports custom guardrails plus Presidio (PII masking). Several built-in callback integrations — including llmguard_moderations, llamaguard_moderations, hide_secrets, openai_moderations, google_text_moderation, lakera_prompt_injection, and aporia_prompt_injection — require a LiteLLM Enterprise license.
Core Enterprise Features
Security & Access Control
- SSO for the Admin UI – Okta, Azure AD, Google Workspace, and any OIDC/SAML provider
- JWT-based Authentication – Authenticate requests with your identity provider's tokens
- Audit Logs with retention policies – Track every admin action and key-level change
- Role-Based Access Control – Organizations, teams, and user roles
- Public & private route controls – Restrict admin routes, lock down surface area
- IP address-based access control lists – Restrict proxy access to specific CIDR ranges
- Key Rotations – Automate rotation for virtual keys
- Secret Managers – AWS KMS, AWS Secrets Manager, Azure Key Vault, Google KMS, Google Secret Manager, HashiCorp Vault, CyberArk, or a custom secret manager
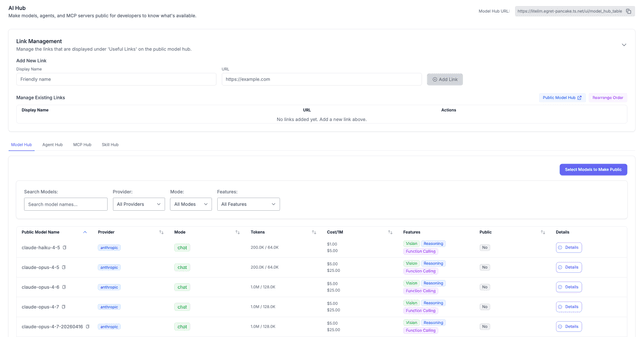
- AI Hub – Share a public, branded page of available models and agents with your users
Governance & Cost Control
- Multi-tenant Architecture – Organizations → Teams → Projects → Keys
- Project Management – Group keys by application or use-case with budgets, owners, and isolated spend tracking
- Tag-based Budgets – Budgets and spend tracking by custom tag
- Model-specific Budgets per Virtual Key – Different limits per model, per key
- Temporary Budget Increases – Time-boxed spend bumps without permanent changes
- Soft Budget Email Alerts – Warn teams before they hit hard limits
- Generate Spend Reports – Programmatic access to spend by key/team/tag/model
Observability & Compliance
- Team-Based Logging – Route each team's logs to their own Langfuse project or callback
- Disable logging per team – GDPR-friendly opt-out at the team level
- Log export to GCS / Azure Blob – Durable storage for compliance
- Guardrails per key/team – Secret redaction, content moderation, banned keywords
- Enforced required params – Reject requests missing required metadata
Operations & Branding
- Custom Swagger branding – Your title, description, and filtered routes
- Custom email branding – Your logo and colors on system emails
- Max request/response size limits – Protect the proxy from runaway payloads
- Team-managed models – Let teams bring their own keys and fine-tunes
Projects
Projects let you group virtual keys by application or use-case. Each project has its own budget, owners, rate limits, and isolated spend view — useful when a single team runs multiple apps and needs separate reporting per app.
- Group keys by application, environment, or customer
- Per-project budgets, rate limits, and model allowlists
- Dedicated owners and spend dashboards
- Works with organizations, teams, and tags
See Project Management and the UI walkthrough for setup.
Deployment Options
Self-Hosted
Deploy our Docker image (or build from the pip package) on your own infrastructure. We provide a license key that unlocks the enterprise features above, plus a dedicated support channel.
LITELLM_LICENSE="eyJ..."
No data leaves your environment. Procurement available via AWS and Azure Marketplace.
Pricing depends on your deployment size — get in touch to scope it.
Professional Support
Standard Support (included)
Included with every enterprise license: a dedicated Slack/Teams channel with our engineering team for integration, deployment, and provider troubleshooting. Support hours are 9am to 9pm PST, Monday through Friday. No guaranteed response time is included.
24/7 Support SLAs (additional fee)
For teams that need guaranteed response times around the clock, we offer 24/7 Support SLAs for an additional fee on top of standard support.
| Severity | Response SLA |
|---|---|
| Sev 0 — 100% production traffic failing | 1 hour |
| Sev 1 — partial production impact | 6 hours |
| Sev 2–3 — setup issues, non-urgent bugs | 24 hours (7am–7pm PT, Mon–Sat) |
| Security patches | 72 hours |
Custom SLAs available on request.
Version support
LiteLLM supports the four most recent stable minor lines. Each of those lines keeps getting patch releases; anything older reaches end of life and stops receiving updates. This policy takes effect Monday, June 29, 2026. As of mid-June 2026 the supported lines are 1.86, 1.87, 1.88, and 1.89, and the set rolls forward as new stable releases ship.
Why we are doing this. LiteLLM ships fast, with a new minor line going out roughly every week. Patching lines well down the list meant carrying every fix forward onto every line we kept alive, a cost that grows with the number of lines we maintain rather than the number of fixes we make. Focusing on four lines lets us give each one more care.
How it works. The window always holds the four most recent stable minor lines. When we promote a new line, the oldest one drops out and stops receiving releases. End of life is a clean cutoff; there is no separate long-term maintenance track. For any supported line, the recommended build is its latest patch. For rare, high-severity issues we will use our judgment and may act beyond the window when the situation calls for it.
What it means for you. To check where you stand, take the latest stable line and count back four; if your version is older than that, plan an upgrade. The simplest path is to pin to a minor line, take its patches, and move onto a newer line before yours drops out.
Public AI Hub
Share a public page of available models, MCP, Agents and skills for users
Secret Managers
LiteLLM Enterprise integrates with the following secret managers:
- AWS KMS
- AWS Secrets Manager
- Azure Key Vault
- Google KMS
- Google Secret Manager
- HashiCorp Vault
- CyberArk
- Custom Secret Manager
See the Secret Managers overview for setup.
Enterprise Feature Reference
The rest of this page is the full feature reference — configuration snippets and examples for each enterprise capability.
💸 Spend Tracking
Viewing Spend per tag
/spend/tags Request Format
curl -X GET "http://0.0.0.0:4000/spend/tags" \
-H "Authorization: Bearer sk-1234"
/spend/tagsResponse Format
[
{
"individual_request_tag": "model-anthropic-claude-v2.1",
"log_count": 6,
"total_spend": 0.000672
},
{
"individual_request_tag": "app-ishaan-local",
"log_count": 4,
"total_spend": 0.000448
},
{
"individual_request_tag": "app-ishaan-prod",
"log_count": 2,
"total_spend": 0.000224
}
]
For comprehensive spend tracking features including budgets, alerts, and detailed analytics, check out Spend Tracking.
Blocking web crawlers
To block web crawlers from indexing the proxy server endpoints, set the block_robots setting to true in your litellm_config.yaml file.
general_settings:
block_robots: true
How it works
When this is enabled, the /robots.txt endpoint will return a 200 status code with the following content:
User-agent: *
Disallow: /
Required Params for LLM Requests
Use this when you want to enforce all requests to include certain params. Example you need all requests to include the user and ["metadata]["generation_name"] params.
- Set on Config
- Set on Key
Step 1 Define all Params you want to enforce on config.yaml
This means ["user"] and ["metadata]["generation_name"] are required in all LLM Requests to LiteLLM
general_settings:
master_key: sk-1234
enforced_params:
- user
- metadata.generation_name
curl -L -X POST 'http://0.0.0.0:4000/key/generate' \
-H 'Authorization: Bearer sk-1234' \
-H 'Content-Type: application/json' \
-d '{
"enforced_params": ["user", "metadata.generation_name"]
}'
Step 2 Verify if this works
- Invalid Request (No `user` passed)
- Invalid Request (No `metadata` passed)
- Valid Request
curl --location 'http://localhost:4000/chat/completions' \
--header 'Authorization: Bearer sk-5fmYeaUEbAMpwBNT-QpxyA' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "hi"
}
]
}'
Expected Response
{"error":{"message":"Authentication Error, BadRequest please pass param=user in request body. This is a required param","type":"auth_error","param":"None","code":401}}%
curl --location 'http://localhost:4000/chat/completions' \
--header 'Authorization: Bearer sk-5fmYeaUEbAMpwBNT-QpxyA' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-3.5-turbo",
"user": "gm",
"messages": [
{
"role": "user",
"content": "hi"
}
],
"metadata": {}
}'
Expected Response
{"error":{"message":"Authentication Error, BadRequest please pass param=[metadata][generation_name] in request body. This is a required param","type":"auth_error","param":"None","code":401}}%
curl --location 'http://localhost:4000/chat/completions' \
--header 'Authorization: Bearer sk-5fmYeaUEbAMpwBNT-QpxyA' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-3.5-turbo",
"user": "gm",
"messages": [
{
"role": "user",
"content": "hi"
}
],
"metadata": {"generation_name": "prod-app"}
}'
Expected Response
{"id":"chatcmpl-9XALnHqkCBMBKrOx7Abg0hURHqYtY","choices":[{"finish_reason":"stop","index":0,"message":{"content":"Hello! How can I assist you today?","role":"assistant"}}],"created":1717691639,"model":"gpt-3.5-turbo-0125","object":"chat.completion","system_fingerprint":null,"usage":{"completion_tokens":9,"prompt_tokens":8,"total_tokens":17}}%
Control available public, private routes
See Control Public & Private Routes for detailed documentation on configuring public routes, admin-only routes, allowed routes, and wildcard patterns.
Guardrails - Secret Detection/Redaction
❓ Use this to REDACT API Keys, Secrets sent in requests to an LLM.
Example if you want to redact the value of OPENAI_API_KEY in the following request
Incoming Request
{
"messages": [
{
"role": "user",
"content": "Hey, how's it going, API_KEY = 'sk_1234567890abcdef'",
}
]
}
Request after Moderation
{
"messages": [
{
"role": "user",
"content": "Hey, how's it going, API_KEY = '[REDACTED]'",
}
]
}
Usage
Step 1 Add this to your config.yaml
litellm_settings:
callbacks: ["hide_secrets"]
Step 2 Run litellm proxy with --detailed_debug to see the server logs
litellm --config config.yaml --detailed_debug
Step 3 Test it with request
Send this request
curl --location 'http://localhost:4000/chat/completions' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"model": "llama3",
"messages": [
{
"role": "user",
"content": "what is the value of my open ai key? openai_api_key=sk-1234998222"
}
]
}'
Expect to see the following warning on your litellm server logs
LiteLLM Proxy:WARNING: secret_detection.py:88 - Detected and redacted secrets in message: ['Secret Keyword']
You can also see the raw request sent from litellm to the API Provider
POST Request Sent from LiteLLM:
curl -X POST \
https://api.groq.com/openai/v1/ \
-H 'Authorization: Bearer gsk_mySVchjY********************************************' \
-d {
"model": "llama3-8b-8192",
"messages": [
{
"role": "user",
"content": "what is the time today, openai_api_key=[REDACTED]"
}
],
"stream": false,
"extra_body": {}
}
Secret Detection On/Off per API Key
❓ Use this when you need to switch guardrails on/off per API Key
Step 1 Create Key with hide_secrets Off
👉 Set "permissions": {"hide_secrets": false} with either /key/generate or /key/update
This means the hide_secrets guardrail is off for all requests from this API Key
- /key/generate
- /key/update
curl --location 'http://0.0.0.0:4000/key/generate' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"permissions": {"hide_secrets": false}
}'
# {"permissions":{"hide_secrets":false},"key":"sk-jNm1Zar7XfNdZXp49Z1kSQ"}
curl --location 'http://0.0.0.0:4000/key/update' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"key": "sk-jNm1Zar7XfNdZXp49Z1kSQ",
"permissions": {"hide_secrets": false}
}'
# {"permissions":{"hide_secrets":false},"key":"sk-jNm1Zar7XfNdZXp49Z1kSQ"}
Step 2 Test it with new key
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-jNm1Zar7XfNdZXp49Z1kSQ' \
--header 'Content-Type: application/json' \
--data '{
"model": "llama3",
"messages": [
{
"role": "user",
"content": "does my openai key look well formatted OpenAI_API_KEY=sk-1234777"
}
]
}'
Expect to see sk-1234777 in your server logs on your callback.
The hide_secrets guardrail check did not run on this request because api key=sk-jNm1Zar7XfNdZXp49Z1kSQ has "permissions": {"hide_secrets": false}
Content Moderation
Content Moderation with LLM Guard
llmguard_moderations requires a LiteLLM Enterprise license and the litellm-enterprise package. The OSS guardrail framework still supports custom guardrails and Presidio PII masking.
Set the LLM Guard API Base in your environment
LLM_GUARD_API_BASE = "http://0.0.0.0:8192" # deployed llm guard api
Add llmguard_moderations as a callback
litellm_settings:
callbacks: ["llmguard_moderations"]
Now you can easily test it
-
Make a regular /chat/completion call
-
Check your proxy logs for any statement with
LLM Guard:
Expected results:
LLM Guard: Received response - {"sanitized_prompt": "hello world", "is_valid": true, "scanners": { "Regex": 0.0 }}
Turn on/off per key
1. Update config
litellm_settings:
callbacks: ["llmguard_moderations"]
llm_guard_mode: "key-specific"
2. Create new key
curl --location 'http://localhost:4000/key/generate' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"models": ["fake-openai-endpoint"],
"permissions": {
"enable_llm_guard_check": true # 👈 KEY CHANGE
}
}'
# Returns {..'key': 'my-new-key'}
3. Test it!
curl --location 'http://0.0.0.0:4000/v1/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer my-new-key' \ # 👈 TEST KEY
--data '{"model": "fake-openai-endpoint", "messages": [
{"role": "system", "content": "Be helpful"},
{"role": "user", "content": "What do you know?"}
]
}'
Turn on/off per request
1. Update config
litellm_settings:
callbacks: ["llmguard_moderations"]
llm_guard_mode: "request-specific"
2. Create new key
curl --location 'http://localhost:4000/key/generate' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"models": ["fake-openai-endpoint"],
}'
# Returns {..'key': 'my-new-key'}
3. Test it!
- OpenAI Python v1.0.0+
- Curl Request
import openai
client = openai.OpenAI(
api_key="sk-1234",
base_url="http://0.0.0.0:4000"
)
# request sent to model set on litellm proxy, `litellm --model`
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages = [
{
"role": "user",
"content": "this is a test request, write a short poem"
}
],
extra_body={ # pass in any provider-specific param, if not supported by openai, https://docs.litellm.ai/docs/completion/input#provider-specific-params
"metadata": {
"permissions": {
"enable_llm_guard_check": True # 👈 KEY CHANGE
},
}
}
)
print(response)
curl --location 'http://0.0.0.0:4000/v1/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer my-new-key' \ # 👈 TEST KEY
--data '{"model": "fake-openai-endpoint", "messages": [
{"role": "system", "content": "Be helpful"},
{"role": "user", "content": "What do you know?"}
]
}'
Content Moderation with LlamaGuard
Currently works with Sagemaker's LlamaGuard endpoint.
How to enable this in your config.yaml:
litellm_settings:
callbacks: ["llamaguard_moderations"]
llamaguard_model_name: "sagemaker/jumpstart-dft-meta-textgeneration-llama-guard-7b"
Make sure you have the relevant keys in your environment, eg.:
os.environ["AWS_ACCESS_KEY_ID"] = ""
os.environ["AWS_SECRET_ACCESS_KEY"] = ""
os.environ["AWS_REGION_NAME"] = ""
Customize LlamaGuard prompt
To modify the unsafe categories llama guard evaluates against, just create your own version of this category list
Point your proxy to it
callbacks: ["llamaguard_moderations"]
llamaguard_model_name: "sagemaker/jumpstart-dft-meta-textgeneration-llama-guard-7b"
llamaguard_unsafe_content_categories: /path/to/llamaguard_prompt.txt
Content Moderation with Google Text Moderation
Requires your GOOGLE_APPLICATION_CREDENTIALS to be set in your .env (same as VertexAI).
How to enable this in your config.yaml:
litellm_settings:
callbacks: ["google_text_moderation"]
Set custom confidence thresholds
Google Moderations checks the test against several categories. Source
Set global default confidence threshold
By default this is set to 0.8. But you can override this in your config.yaml.
litellm_settings:
google_moderation_confidence_threshold: 0.4
Set category-specific confidence threshold
Set a category specific confidence threshold in your config.yaml. If none set, the global default will be used.
litellm_settings:
toxic_confidence_threshold: 0.1
Here are the category specific values:
| Category | Setting |
|---|---|
| "toxic" | toxic_confidence_threshold: 0.1 |
| "insult" | insult_confidence_threshold: 0.1 |
| "profanity" | profanity_confidence_threshold: 0.1 |
| "derogatory" | derogatory_confidence_threshold: 0.1 |
| "sexual" | sexual_confidence_threshold: 0.1 |
| "death_harm_and_tragedy" | death_harm_and_tragedy_threshold: 0.1 |
| "violent" | violent_threshold: 0.1 |
| "firearms_and_weapons" | firearms_and_weapons_threshold: 0.1 |
| "public_safety" | public_safety_threshold: 0.1 |
| "health" | health_threshold: 0.1 |
| "religion_and_belief" | religion_and_belief_threshold: 0.1 |
| "illicit_drugs" | illicit_drugs_threshold: 0.1 |
| "war_and_conflict" | war_and_conflict_threshold: 0.1 |
| "politics" | politics_threshold: 0.1 |
| "finance" | finance_threshold: 0.1 |
| "legal" | legal_threshold: 0.1 |
Swagger Docs - Custom Routes + Branding
Requires a LiteLLM Enterprise key to use. Get a free 2-week license here
Set LiteLLM Key in your environment
LITELLM_LICENSE=""
Customize Title + Description
In your environment, set:
DOCS_TITLE="TotalGPT"
DOCS_DESCRIPTION="Sample Company Description"
Customize Routes
Hide admin routes from users.
In your environment, set:
DOCS_FILTERED="True" # only shows openai routes to user
Enable Blocked User Lists
If any call is made to proxy with this user id, it'll be rejected - use this if you want to let users opt-out of ai features
litellm_settings:
callbacks: ["blocked_user_check"]
blocked_user_list: ["user_id_1", "user_id_2", ...] # can also be a .txt filepath e.g. `/relative/path/blocked_list.txt`
How to test
- OpenAI Python v1.0.0+
- Curl Request
Set user=<user_id> to the user id of the user who might have opted out.
import openai
client = openai.OpenAI(
api_key="sk-1234",
base_url="http://0.0.0.0:4000"
)
# request sent to model set on litellm proxy, `litellm --model`
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages = [
{
"role": "user",
"content": "this is a test request, write a short poem"
}
],
user="user_id_1"
)
print(response)
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
"user": "user_id_1" # this is also an openai supported param
}
'
Using via API
Block all calls for a customer id
curl -X POST "http://0.0.0.0:4000/customer/block" \
-H "Authorization: Bearer sk-1234" \
-D '{
"user_ids": [<user_id>, ...]
}'
Unblock calls for a user id
curl -X POST "http://0.0.0.0:4000/user/unblock" \
-H "Authorization: Bearer sk-1234" \
-D '{
"user_ids": [<user_id>, ...]
}'
Enable Banned Keywords List
litellm_settings:
callbacks: ["banned_keywords"]
banned_keywords_list: ["hello"] # can also be a .txt file - e.g.: `/relative/path/keywords.txt`
Test this
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "Hello world!"
}
]
}
'
Set Max Request / Response Size on LiteLLM Proxy
Use this if you want to set a maximum request / response size for your proxy server. If a request size is above the size it gets rejected + slack alert triggered
Usage
Step 1. Set max_request_size_mb and max_response_size_mb
For this example we set a very low limit on max_request_size_mb and expect it to get rejected
In production we recommend setting a max_request_size_mb / max_response_size_mb around 32 MB
model_list:
- model_name: fake-openai-endpoint
litellm_params:
model: openai/fake
api_key: fake-key
api_base: https://exampleopenaiendpoint-production.up.railway.app/
general_settings:
master_key: sk-1234
# Security controls
max_request_size_mb: 0.000000001 # 👈 Key Change - Max Request Size in MB. Set this very low for testing
max_response_size_mb: 100 # 👈 Key Change - Max Response Size in MB
Step 2. Test it with /chat/completions request
curl http://localhost:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234" \
-d '{
"model": "fake-openai-endpoint",
"messages": [
{"role": "user", "content": "Hello, Claude!"}
]
}'
Expected Response from request
We expect this to fail since the request size is over max_request_size_mb
{"error":{"message":"Request size is too large. Request size is 0.0001125335693359375 MB. Max size is 1e-09 MB","type":"bad_request_error","param":"content-length","code":400}}
FAQ
How do I set up and verify an Enterprise License?
-
Add the license key to your environment:
LITELLM_LICENSE="eyJ..." -
Restart LiteLLM Proxy.
-
Open
http://<your-proxy-host>:<port>/— the Swagger page should show "Enterprise Edition" in the description. If it doesn't, confirm the key is correct, unexpired, and that the proxy was fully restarted.
Where can I read more about data security and compliance?
See Data Security / Legal / Compliance FAQs.
How is pricing structured?
Pricing is based on usage. Contact us for a quote tailored to your team.
How do I get day-0 support for new models without restarting?
Use Auto Sync New Models to pull the latest pricing and context-window data from GitHub on demand or on a schedule — no restart required. Trigger a manual sync with POST /reload/model_cost_map, or schedule periodic syncs with POST /schedule/model_cost_map_reload?hours=6.