LiteLLM Proxy - Locust Load Test
Locust Load Test LiteLLM Proxy
- Add
fake-openai-endpointto your proxy config.yaml and start your litellm proxy.
LiteLLM provides a free hosted fake-openai-endpoint you can load test against. You can also self-host your own fake OpenAI proxy server using github.com/BerriAI/example_openai_endpoint.
model_list:
- model_name: fake-openai-endpoint
litellm_params:
model: openai/fake
api_key: fake-key
api_base: https://exampleopenaiendpoint-production.up.railway.app/
-
uv add locust -
Create a file called
locustfile.pyon your local machine. Copy the contents from the litellm load test located here -
Start locust Run
locustin the same directory as yourlocustfile.pyfrom step 2
locust
Output on terminal
[2024-03-15 07:19:58,893] Starting web interface at http://0.0.0.0:8089
[2024-03-15 07:19:58,898] Starting Locust 2.24.0
- Run Load test on locust
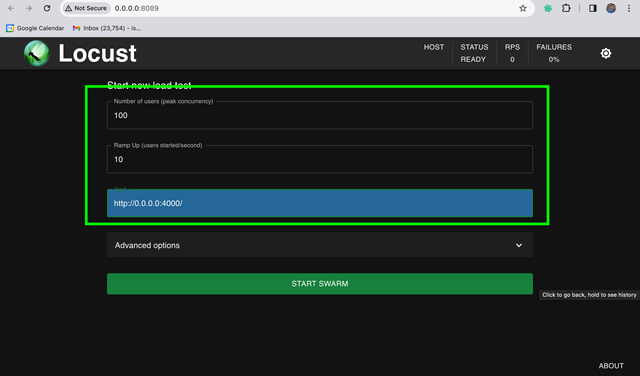
Head to the locust UI on http://0.0.0.0:8089
Set Users=100, Ramp Up Users=10, Host=Base URL of your LiteLLM Proxy
- Expected Results
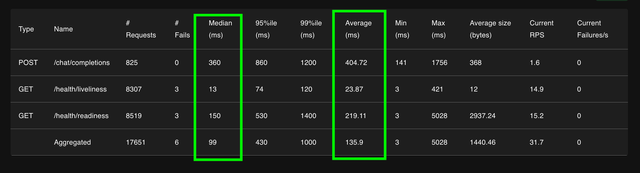
Expect to see the following response times for /health/readiness
Median → /health/readiness is 150ms
Avg → /health/readiness is 219ms