Thank you to everyone who joined our June town hall.
Three numbers capture the month: 24 security fixes, 94 bug fixes, and 78 feature commits. The sections below break each one down, alongside our public commitment to zero reported regressions and the gradual migration of the LiteLLM gateway to Rust.
Over the past year, we have heard the same thing from our users and our community: they want the fastest, most lightweight AI gateway they can run. We have heard you. We are addressing it by moving LiteLLM to Rust, and committing to sub-1ms overhead with a sub-100MB memory binary you can deploy. By the end of this migration, you will get a pure Rust server that can serve 100% of your AI traffic, with every hot path operation, including auth and rate limiting, running in Rust.
Want to help us build it?
We are opening an early beta and want to work directly with teams who care about a fast, lightweight gateway. If that is you, sign up here and we will get you testing the Rust gateway in your own stack, with a direct line to our team.
The reason it matters: under real load, CPU and memory climb with concurrency, and pods get OOM-killed at the worst time. Today the LiteLLM Python proxy peaks around 359MB of memory under load, and that cost multiplies across every pod, region, and retry you run.
We are already seeing the payoff in benchmarks. The Rust gateway serves about 15x the throughput (453 to 6,782 requests per second) on about 11x less memory (359MB to 32MB), and cuts per-request overhead from about 7.5ms on the Python path to about 0.05ms, well under the 1ms we commit to.
You deploy a single Rust binary. It uses about 65MB of memory, gateway overhead stays under 1ms, and nothing in your setup changes: same config.yaml, same database, same client API, same providers. You keep LiteLLM's coverage of 100+ LLM providers behind one OpenAI-compatible API, with /chat/completions, /messages, /responses, and every other LLM endpoint LiteLLM supports today, now as the fastest and most lightweight LLM gateway you can self-host.
This is not a v2 and not a rewrite. There is no new major version to migrate to and nothing for you to change. The runtime under the hot path gets faster and lighter while your config stays exactly where it is.
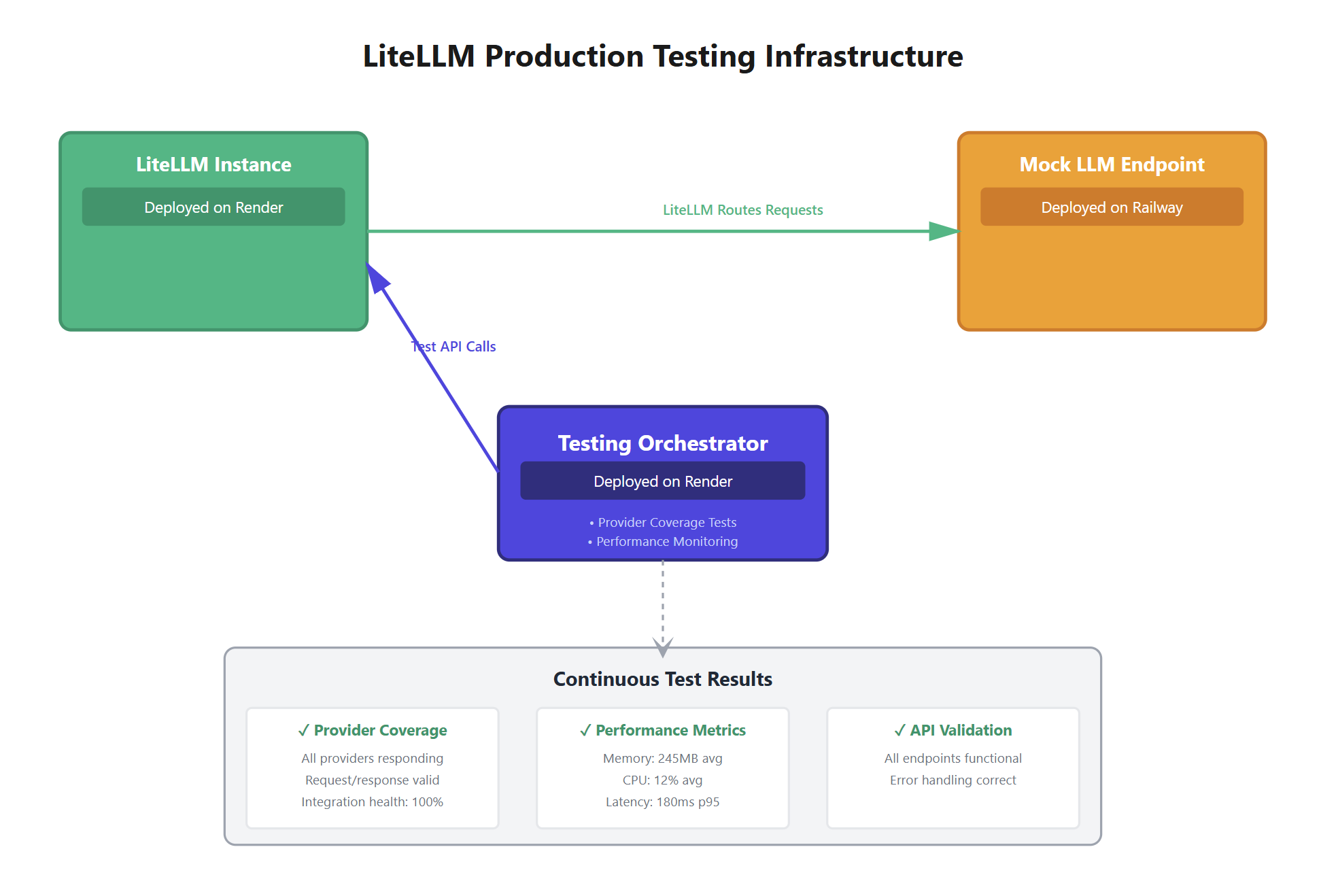
We ship this the careful way. Each route moves to Rust only after it passes our full parity and end-to-end test suite, and it runs in production before the next route starts. Stability is the priority, and we target zero regressions on every release.
The LiteLLM proxy container does 2 very different things. It's an LLM data plane, /chat/completions, /v1/messages, embeddings, passthroughs, where latency is measured in single-digit milliseconds of overhead and traffic is high-volume and bursty. It's also a management control plane — keys, teams, SSO, audit logs, and the spend/usage analytics that power the dashboard, where a single request can scan millions of rows.
Run both on the same event loop, and the slowest thing the control plane does sets the reliability floor for the fastest thing the data plane does. This post is about how we've improved LiteLLM's reliability at scale by offering a componentized deployment model.
Date: April 2026
Duration: Multiple incidents across customer deployments before fix landed
Severity: High — surfaced as full proxy outages in Kubernetes
Status: Resolved
Note: This fix is available starting from the release that contains PR #26225 (merged April 29, 2026).
When the upstream Postgres database became unreachable, the LiteLLM proxy's Prisma reconnect path called await self.db.disconnect(). Under prisma-client-py that call invokes a synchronoussubprocess.Popen.wait() on the Rust query-engine subprocess. Because wait() does not yield, the asyncio event loop froze for as long as the engine took to shut down — typically 30–120 seconds in production when the engine was stuck on TCP close operations against the unresponsive database.
While the loop was frozen, no coroutines ran, including /health/liveliness. Kubernetes liveness probes timed out and the kubelet SIGKILLed the pod. From the operator's point of view the proxy looked dead even though the underlying issue was a transient DB outage that the reconnect logic was supposed to ride through.
Impact: Any customer whose Postgres briefly became unresponsive saw proxy pods get killed and restarted instead of degrading gracefully and reconnecting once the DB came back. Reported externally by FLock and reproduced internally.
Enterprise AI Gateway deployments put Redis in the hot path for nearly every request: rate limiting, cache lookups, spend tracking. When Redis is healthy, the latency contribution is single-digit milliseconds — invisible to end users. When it degrades, a production AI Gateway needs to stay up regardless.
Running LiteLLM at scale across 100+ pods means designing for failure modes before they appear. The easy case is Redis going fully down: fail fast, fall through to the database, continue serving requests. The hard case — the one that takes down gateways — is a slow Redis: still accepting connections, still responding, but timing out after 20-30 seconds per operation.
Thank you to everyone who joined our April town hall.
We used the session to share our CI/CD v2 improvements, product stability work, and what we are prioritizing next across reliability and product roadmap.
As LiteLLM adoption has grown, so have expectations around reliability, performance, and operational safety. Meeting those expectations requires more than correctness-focused tests, it requires validating how the system behaves over time, under real-world conditions.
This post introduces LiteLLM Observatory, a long-running release-validation system we built to catch regressions before they reach users.