Gemini - Google AI Studio
| Property | Details |
|---|---|
| Description | Google AI Studio is a fully-managed AI development platform for building and using generative AI. |
| Provider Route on LiteLLM | gemini/ |
| Provider Doc | Google AI Studio ↗ |
| API Endpoint for Provider | https://generativelanguage.googleapis.com |
| Supported OpenAI Endpoints | /chat/completions, /embeddings, /completions, /videos, /images/edits |
| Lyria (music) | Cost map & notes |
| Pass-through Endpoint | Supported |
| Model Format | Provider | Auth Required |
|---|---|---|
gemini/gemini-2.0-flash | Gemini API | GEMINI_API_KEY (simple API key) |
vertex_ai/gemini-2.0-flash | Vertex AI | GCP credentials + project |
gemini-2.0-flash (no prefix) | Vertex AI | GCP credentials + project |
If you just want to use an API key (like OpenAI), use the gemini/ prefix.
Models without a prefix default to Vertex AI which requires full GCP authentication.
API Keys
import os
os.environ["GEMINI_API_KEY"] = "your-api-key"
Sample Usage
from litellm import completion
import os
os.environ['GEMINI_API_KEY'] = ""
response = completion(
model="gemini/gemini-pro",
messages=[{"role": "user", "content": "write code for saying hi from LiteLLM"}]
)
Supported OpenAI Params
- temperature
- top_p
- max_tokens
- max_completion_tokens
- stream
- tools
- tool_choice
- include_server_side_tool_invocations
- functions
- response_format
- n
- stop
- logprobs
- frequency_penalty
- modalities
- reasoning_content
- audio (for TTS models only)
- service_tier
Anthropic Params
- thinking (used to set max budget tokens across anthropic/gemini models)
Usage - Thinking / reasoning_content
LiteLLM translates OpenAI's reasoning_effort to Gemini's thinking parameter. Code
Cost Optimization: Use reasoning_effort="none" (OpenAI standard) for significant cost savings - up to 96% cheaper. Google's docs
Note: Reasoning cannot be turned off on Gemini 2.5 Pro models.
For Gemini 3+ models (e.g., gemini-3-pro-preview), LiteLLM maps reasoning_effort to the thinking_level field instead of thinking_budget when you set it. Supported levels depend on the model (Flash-family models also support minimal and medium). If you omit reasoning_effort, LiteLLM does not send a default thinking_level — the request uses the Gemini API defaults (Gemini 3 Flash defaults to high on the API).
Gemini image models (e.g., gemini-3-pro-image-preview, gemini-2.0-flash-exp-image-generation) do not support the thinking_level parameter. LiteLLM automatically excludes image models from receiving thinking configuration to prevent API errors.
Mapping for Gemini 2.5 and earlier models
| reasoning_effort | thinking | Notes |
|---|---|---|
| "none" | "budget_tokens": 0, "includeThoughts": false | 💰 Recommended for cost optimization - OpenAI-compatible, always 0 |
| "disable" | "budget_tokens": DEFAULT (0), "includeThoughts": false | LiteLLM-specific, configurable via env var |
| "low" | "budget_tokens": 1024 | |
| "medium" | "budget_tokens": 2048 | |
| "high" | "budget_tokens": 4096 |
Mapping for Gemini 3+ models
| reasoning_effort | thinking_level | Notes |
|---|---|---|
| "minimal" | "minimal" (Flash / some 3.1) or "low" | Flash-family IDs use minimal when supported |
| "low" | "low" | Best for simple instruction following or chat |
| "medium" | "medium" or "high" | "medium" where the API supports it; otherwise "high" |
| "high" | "high" | Maximizes reasoning depth |
| "disable" | "minimal" (Flash) or "low" | Cannot fully disable thinking in Gemini 3 |
| "none" | "minimal" (Flash) or "low" | Cannot fully disable thinking in Gemini 3 |
- SDK
- PROXY
from litellm import completion
# Cost-optimized: Use reasoning_effort="none" for best pricing
resp = completion(
model="gemini/gemini-2.0-flash-thinking-exp-01-21",
messages=[{"role": "user", "content": "What is the capital of France?"}],
reasoning_effort="none", # Up to 96% cheaper!
)
# Or use other levels: "low", "medium", "high"
resp = completion(
model="gemini/gemini-2.5-flash-preview-04-17",
messages=[{"role": "user", "content": "What is the capital of France?"}],
reasoning_effort="low",
)
- Setup config.yaml
- model_name: gemini-2.5-flash
litellm_params:
model: gemini/gemini-2.5-flash-preview-04-17
api_key: os.environ/GEMINI_API_KEY
- Start proxy
litellm --config /path/to/config.yaml
- Test it!
curl http://0.0.0.0:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR-LITELLM-KEY>" \
-d '{
"model": "gemini-2.5-flash",
"messages": [{"role": "user", "content": "What is the capital of France?"}],
"reasoning_effort": "low"
}'
Gemini 3+ Models - thinking_level Parameter
For Gemini 3+ models (e.g., gemini-3-pro-preview), you can use the new thinking_level parameter directly:
- SDK
- PROXY
from litellm import completion
# Use thinking_level for Gemini 3 models
resp = completion(
model="gemini/gemini-3-pro-preview",
messages=[{"role": "user", "content": "Solve this complex math problem step by step."}],
reasoning_effort="high", # Options: "low" or "high"
)
# Low thinking level for faster, simpler tasks
resp = completion(
model="gemini/gemini-3-pro-preview",
messages=[{"role": "user", "content": "What is the weather today?"}],
reasoning_effort="low", # Minimizes latency and cost
)
curl http://0.0.0.0:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR-LITELLM-KEY>" \
-d '{
"model": "gemini-3-pro-preview",
"messages": [{"role": "user", "content": "Solve this complex problem."}],
"reasoning_effort": "high"
}'
Temperature Recommendation for Gemini 3 Models
For Gemini 3 models, LiteLLM defaults temperature to 1.0 and strongly recommends keeping it at this default. Setting temperature < 1.0 can cause:
- Infinite loops
- Degraded reasoning performance
- Failure on complex tasks
LiteLLM will automatically set temperature=1.0 if not specified for Gemini 3+ models.
Expected Response
ModelResponse(
id='chatcmpl-c542d76d-f675-4e87-8e5f-05855f5d0f5e',
created=1740470510,
model='claude-3-7-sonnet-20250219',
object='chat.completion',
system_fingerprint=None,
choices=[
Choices(
finish_reason='stop',
index=0,
message=Message(
content="The capital of France is Paris.",
role='assistant',
tool_calls=None,
function_call=None,
reasoning_content='The capital of France is Paris. This is a very straightforward factual question.'
),
)
],
usage=Usage(
completion_tokens=68,
prompt_tokens=42,
total_tokens=110,
completion_tokens_details=None,
prompt_tokens_details=PromptTokensDetailsWrapper(
audio_tokens=None,
cached_tokens=0,
text_tokens=None,
image_tokens=None
),
cache_creation_input_tokens=0,
cache_read_input_tokens=0
)
)
Pass thinking to Gemini models
You can also pass the thinking parameter to Gemini models.
This is translated to Gemini's thinkingConfig parameter.
- SDK
- PROXY
response = litellm.completion(
model="gemini/gemini-2.5-flash-preview-04-17",
messages=[{"role": "user", "content": "What is the capital of France?"}],
thinking={"type": "enabled", "budget_tokens": 1024},
)
curl http://0.0.0.0:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $LITELLM_KEY" \
-d '{
"model": "gemini/gemini-2.5-flash-preview-04-17",
"messages": [{"role": "user", "content": "What is the capital of France?"}],
"thinking": {"type": "enabled", "budget_tokens": 1024}
}'
For Gemini 3+ models, LiteLLM now follows provider defaults by default and does not force thinkingLevel when you pass Anthropic-style thinking={"type":"enabled","budget_tokens":...}.
If you want the legacy LiteLLM behavior (force thinkingLevel="low" for Pro and thinkingLevel="minimal" for Flash), enable:
import litellm
litellm.enable_gemini_default_thinking_level_low = True
Usage - service_tier
LiteLLM propagates OpenAI's service_tier parameter to Gemini, and also extracts it from the response headers (x-gemini-service-tier) into model_response.service_tier.
OpenAI service_tier | Gemini service_tier | Notes |
|---|---|---|
"auto" | "priority" | LiteLLM maps OpenAI's "auto" to Gemini's "priority" tier, as priority will fall back on Gemini. |
"flex" | "flex" | Direct mapping. |
"priority" | "priority" | Direct mapping. |
"default" | "standard" | LiteLLM maps "default" to "standard". |
| Any other value | Passed as-is (lowercased) | Values are case-insensitive and normalized to lowercase. |
On the response, LiteLLM maps "standard" back to "default" for the Gemini API.
Text-to-Speech (TTS) Audio Output
LiteLLM supports Gemini TTS models that can generate audio responses using the OpenAI-compatible audio parameter format.
Supported Models
LiteLLM supports Gemini TTS models with audio capabilities (e.g. gemini-2.5-flash-preview-tts and gemini-2.5-pro-preview-tts). For the complete list of available TTS models and voices, see the official Gemini TTS documentation.
Limitations
Important Limitations:
- Gemini TTS models only support the
pcm16audio format - Streaming support has not been added to TTS models yet
- The
modalitiesparameter must be set to['audio']for TTS requests
Quick Start
- SDK
- PROXY
from litellm import completion
import os
os.environ['GEMINI_API_KEY'] = "your-api-key"
response = completion(
model="gemini/gemini-2.5-flash-preview-tts",
messages=[{"role": "user", "content": "Say hello in a friendly voice"}],
modalities=["audio"], # Required for TTS models
audio={
"voice": "Kore",
"format": "pcm16" # Required: must be "pcm16"
}
)
print(response)
- Setup config.yaml
model_list:
- model_name: gemini-tts-flash
litellm_params:
model: gemini/gemini-2.5-flash-preview-tts
api_key: os.environ/GEMINI_API_KEY
- model_name: gemini-tts-pro
litellm_params:
model: gemini/gemini-2.5-pro-preview-tts
api_key: os.environ/GEMINI_API_KEY
- Start proxy
litellm --config /path/to/config.yaml
- Make TTS request
curl http://0.0.0.0:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR-LITELLM-KEY>" \
-d '{
"model": "gemini-tts-flash",
"messages": [{"role": "user", "content": "Say hello in a friendly voice"}],
"modalities": ["audio"],
"audio": {
"voice": "Kore",
"format": "pcm16"
}
}'
Advanced Usage
You can combine TTS with other Gemini features:
response = completion(
model="gemini/gemini-2.5-pro-preview-tts",
messages=[
{"role": "system", "content": "You are a helpful assistant that speaks clearly."},
{"role": "user", "content": "Explain quantum computing in simple terms"}
],
modalities=["audio"],
audio={
"voice": "Charon",
"format": "pcm16"
},
temperature=0.7,
max_tokens=150
)
For more information about Gemini's TTS capabilities and available voices, see the official Gemini TTS documentation.
Passing Gemini Specific Params
Response schema
LiteLLM supports sending response_schema as a param for Gemini-1.5-Pro on Google AI Studio.
Response Schema
- SDK
- PROXY
from litellm import completion
import json
import os
os.environ['GEMINI_API_KEY'] = ""
messages = [
{
"role": "user",
"content": "List 5 popular cookie recipes."
}
]
response_schema = {
"type": "array",
"items": {
"type": "object",
"properties": {
"recipe_name": {
"type": "string",
},
},
"required": ["recipe_name"],
},
}
completion(
model="gemini/gemini-1.5-pro",
messages=messages,
response_format={"type": "json_object", "response_schema": response_schema} # 👈 KEY CHANGE
)
print(json.loads(completion.choices[0].message.content))
- Add model to config.yaml
model_list:
- model_name: gemini-pro
litellm_params:
model: gemini/gemini-1.5-pro
api_key: os.environ/GEMINI_API_KEY
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-d '{
"model": "gemini-pro",
"messages": [
{"role": "user", "content": "List 5 popular cookie recipes."}
],
"response_format": {"type": "json_object", "response_schema": {
"type": "array",
"items": {
"type": "object",
"properties": {
"recipe_name": {
"type": "string",
},
},
"required": ["recipe_name"],
},
}}
}
'
Validate Schema
To validate the response_schema, set enforce_validation: true.
- SDK
- PROXY
from litellm import completion, JSONSchemaValidationError
try:
completion(
model="gemini/gemini-1.5-pro",
messages=messages,
response_format={
"type": "json_object",
"response_schema": response_schema,
"enforce_validation": true # 👈 KEY CHANGE
}
)
except JSONSchemaValidationError as e:
print("Raw Response: {}".format(e.raw_response))
raise e
- Add model to config.yaml
model_list:
- model_name: gemini-pro
litellm_params:
model: gemini/gemini-1.5-pro
api_key: os.environ/GEMINI_API_KEY
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-d '{
"model": "gemini-pro",
"messages": [
{"role": "user", "content": "List 5 popular cookie recipes."}
],
"response_format": {"type": "json_object", "response_schema": {
"type": "array",
"items": {
"type": "object",
"properties": {
"recipe_name": {
"type": "string",
},
},
"required": ["recipe_name"],
},
},
"enforce_validation": true
}
}
'
LiteLLM will validate the response against the schema, and raise a JSONSchemaValidationError if the response does not match the schema.
JSONSchemaValidationError inherits from openai.APIError
Access the raw response with e.raw_response
GenerationConfig Params
To pass additional GenerationConfig params - e.g. topK, just pass it in the request body of the call, and LiteLLM will pass it straight through as a key-value pair in the request body.
See Gemini GenerationConfigParams
- SDK
- PROXY
from litellm import completion
import json
import os
os.environ['GEMINI_API_KEY'] = ""
messages = [
{
"role": "user",
"content": "List 5 popular cookie recipes."
}
]
completion(
model="gemini/gemini-1.5-pro",
messages=messages,
topK=1 # 👈 KEY CHANGE
)
print(json.loads(completion.choices[0].message.content))
- Add model to config.yaml
model_list:
- model_name: gemini-pro
litellm_params:
model: gemini/gemini-1.5-pro
api_key: os.environ/GEMINI_API_KEY
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-d '{
"model": "gemini-pro",
"messages": [
{"role": "user", "content": "List 5 popular cookie recipes."}
],
"topK": 1 # 👈 KEY CHANGE
}
'
Validate Schema
To validate the response_schema, set enforce_validation: true.
- SDK
- PROXY
from litellm import completion, JSONSchemaValidationError
try:
completion(
model="gemini/gemini-1.5-pro",
messages=messages,
response_format={
"type": "json_object",
"response_schema": response_schema,
"enforce_validation": true # 👈 KEY CHANGE
}
)
except JSONSchemaValidationError as e:
print("Raw Response: {}".format(e.raw_response))
raise e
- Add model to config.yaml
model_list:
- model_name: gemini-pro
litellm_params:
model: gemini/gemini-1.5-pro
api_key: os.environ/GEMINI_API_KEY
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-d '{
"model": "gemini-pro",
"messages": [
{"role": "user", "content": "List 5 popular cookie recipes."}
],
"response_format": {"type": "json_object", "response_schema": {
"type": "array",
"items": {
"type": "object",
"properties": {
"recipe_name": {
"type": "string",
},
},
"required": ["recipe_name"],
},
},
"enforce_validation": true
}
}
'
Specifying Safety Settings
In certain use-cases you may need to make calls to the models and pass safety settings different from the defaults. To do so, simple pass the safety_settings argument to completion or acompletion. For example:
response = completion(
model="gemini/gemini-pro",
messages=[{"role": "user", "content": "write code for saying hi from LiteLLM"}],
safety_settings=[
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_NONE",
},
]
)
Tool Calling
from litellm import completion
import os
# set env
os.environ["GEMINI_API_KEY"] = ".."
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
},
}
]
messages = [{"role": "user", "content": "What's the weather like in Boston today?"}]
response = completion(
model="gemini/gemini-1.5-flash",
messages=messages,
tools=tools,
)
# Add any assertions, here to check response args
print(response)
assert isinstance(response.choices[0].message.tool_calls[0].function.name, str)
assert isinstance(
response.choices[0].message.tool_calls[0].function.arguments, str
)
Google Search Tool
- SDK
- PROXY
from litellm import completion
import os
os.environ["GEMINI_API_KEY"] = ".."
tools = [{"googleSearch": {}}] # 👈 ADD GOOGLE SEARCH
response = completion(
model="gemini/gemini-2.0-flash",
messages=[{"role": "user", "content": "What is the weather in San Francisco?"}],
tools=tools,
)
print(response)
- Setup config.yaml
model_list:
- model_name: gemini-2.0-flash
litellm_params:
model: gemini/gemini-2.0-flash
api_key: os.environ/GEMINI_API_KEY
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-d '{
"model": "gemini-2.0-flash",
"messages": [{"role": "user", "content": "What is the weather in San Francisco?"}],
"tools": [{"googleSearch": {}}]
}
'
Context Circulation (Server-Side Tool Combination)
Context circulation allows Gemini 3+ models to combine built-in tools (like Google Search) with your custom functions in the same request. Without it, Gemini returns an error if you try to use both.
When enabled, Gemini can execute Google Search server-side, use those results to decide whether to call your custom functions, and return the full chain of reasoning.
How it works:
- You pass
include_server_side_tool_invocations=Truealong with both Google Search and your function tools - Gemini executes server-side tools internally and returns
toolCall/toolResponseparts alongside anyfunctionCallparts - LiteLLM extracts the server-side invocations into
provider_specific_fields["server_side_tool_invocations"] - On subsequent turns, include the full assistant message in your conversation history — LiteLLM re-injects the server-side parts automatically
- SDK
- PROXY
from litellm import completion
response = completion(
model="gemini/gemini-3-flash-preview",
messages=[{"role": "user", "content": "What's the weather in Buenos Aires? If it's raining, schedule a meeting."}],
tools=[
{"type": "web_search_preview"}, # Google Search (server-side)
{
"type": "function",
"function": {
"name": "schedule_meeting",
"description": "Schedule a meeting",
"parameters": {
"type": "object",
"properties": {"reason": {"type": "string"}},
"required": ["reason"],
},
},
},
],
include_server_side_tool_invocations=True,
)
msg = response.choices[0].message
# Server-side tool results are in provider_specific_fields
psf = msg.provider_specific_fields or {}
for invocation in psf.get("server_side_tool_invocations", []):
print(invocation["tool_type"]) # e.g. "GOOGLE_SEARCH_WEB"
print(invocation["id"])
print(invocation["args"]) # e.g. {"queries": ["weather Buenos Aires"]}
print(invocation["response"]) # Search results from Google
# For multi-turn: just append the full message to history
messages.append(msg)
messages.append({"role": "user", "content": "Thanks!"})
# LiteLLM automatically re-injects the server-side parts + thought signatures
response2 = completion(
model="gemini/gemini-3-flash-preview",
messages=messages,
tools=tools,
include_server_side_tool_invocations=True,
)
- Setup config.yaml
model_list:
- model_name: gemini-3-flash
litellm_params:
model: gemini/gemini-3-flash-preview
api_key: os.environ/GEMINI_API_KEY
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-d '{
"model": "gemini-3-flash",
"messages": [{"role": "user", "content": "What is the weather in Buenos Aires?"}],
"tools": [
{"type": "web_search_preview"},
{"type": "function", "function": {"name": "schedule_meeting", "description": "Schedule a meeting", "parameters": {"type": "object", "properties": {"reason": {"type": "string"}}}}}
],
"include_server_side_tool_invocations": true
}'
- Context circulation requires Gemini 3+ models
- Server-side tool invocations (
toolCall/toolResponse) are not included intool_calls— they are inprovider_specific_fields["server_side_tool_invocations"]because they were already executed by Google, not by your code thought_signaturesare automatically preserved alongside server-side invocations for multi-turn coherence
URL Context
- SDK
- PROXY
from litellm import completion
import os
os.environ["GEMINI_API_KEY"] = ".."
# 👇 ADD URL CONTEXT
tools = [{"urlContext": {}}]
response = completion(
model="gemini/gemini-2.0-flash",
messages=[{"role": "user", "content": "Summarize this document: https://ai.google.dev/gemini-api/docs/models"}],
tools=tools,
)
print(response)
# Access URL context metadata
url_context_metadata = response.model_extra['vertex_ai_url_context_metadata']
urlMetadata = url_context_metadata[0]['urlMetadata'][0]
print(f"Retrieved URL: {urlMetadata['retrievedUrl']}")
print(f"Retrieval Status: {urlMetadata['urlRetrievalStatus']}")
- Setup config.yaml
model_list:
- model_name: gemini-2.0-flash
litellm_params:
model: gemini/gemini-2.0-flash
api_key: os.environ/GEMINI_API_KEY
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR-LITELLM-KEY>" \
-d '{
"model": "gemini-2.0-flash",
"messages": [{"role": "user", "content": "Summarize this document: https://ai.google.dev/gemini-api/docs/models"}],
"tools": [{"urlContext": {}}]
}'
Google Search Retrieval
- SDK
- PROXY
from litellm import completion
import os
os.environ["GEMINI_API_KEY"] = ".."
tools = [{"googleSearch": {}}] # 👈 ADD GOOGLE SEARCH
response = completion(
model="gemini/gemini-2.0-flash",
messages=[{"role": "user", "content": "What is the weather in San Francisco?"}],
tools=tools,
)
print(response)
- Setup config.yaml
model_list:
- model_name: gemini-2.0-flash
litellm_params:
model: gemini/gemini-2.0-flash
api_key: os.environ/GEMINI_API_KEY
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-d '{
"model": "gemini-2.0-flash",
"messages": [{"role": "user", "content": "What is the weather in San Francisco?"}],
"tools": [{"googleSearch": {}}]
}
'
Code Execution Tool
- SDK
- PROXY
from litellm import completion
import os
os.environ["GEMINI_API_KEY"] = ".."
tools = [{"codeExecution": {}}] # 👈 ADD GOOGLE SEARCH
response = completion(
model="gemini/gemini-2.0-flash",
messages=[{"role": "user", "content": "What is the weather in San Francisco?"}],
tools=tools,
)
print(response)
- Setup config.yaml
model_list:
- model_name: gemini-2.0-flash
litellm_params:
model: gemini/gemini-2.0-flash
api_key: os.environ/GEMINI_API_KEY
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-d '{
"model": "gemini-2.0-flash",
"messages": [{"role": "user", "content": "What is the weather in San Francisco?"}],
"tools": [{"codeExecution": {}}]
}
'
Computer Use Tool
- LiteLLM Python SDK
- LiteLLM Proxy Server
from litellm import completion
import os
os.environ["GEMINI_API_KEY"] = "your-api-key"
# Computer Use tool with browser environment
tools = [
{
"type": "computer_use",
"environment": "browser", # optional: "browser" or "unspecified"
"excluded_predefined_functions": ["drag_and_drop"] # optional
}
]
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Navigate to google.com and search for 'LiteLLM'"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,..." # screenshot of current browser state
}
}
]
}
]
response = completion(
model="gemini/gemini-2.5-computer-use-preview-10-2025",
messages=messages,
tools=tools,
)
print(response)
# Handling tool responses with screenshots
# When the model makes a tool call, send the response back with a screenshot:
if response.choices[0].message.tool_calls:
tool_call = response.choices[0].message.tool_calls[0]
# Add assistant message with tool call
messages.append(response.choices[0].message.model_dump())
# Add tool response with screenshot
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": [
{
"type": "text",
"text": '{"url": "https://example.com", "status": "completed"}'
},
{
"type": "input_image",
"image_url": "data:image/png;base64,..." # New screenshot after action (Can send an image url as well, litellm handles the conversion)
}
]
})
# Continue conversation with updated screenshot
response = completion(
model="gemini/gemini-2.5-computer-use-preview-10-2025",
messages=messages,
tools=tools,
)
- Add model to config.yaml
model_list:
- model_name: gemini-computer-use
litellm_params:
model: gemini/gemini-2.5-computer-use-preview-10-2025
api_key: os.environ/GEMINI_API_KEY
- Start proxy
litellm --config /path/to/config.yaml
- Make request
curl http://0.0.0.0:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234" \
-d '{
"model": "gemini-computer-use",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Click on the search button"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,..."
}
}
]
}
],
"tools": [
{
"type": "computer_use",
"environment": "browser"
}
]
}'
Tool Response Format:
When responding to Computer Use tool calls, include the URL and screenshot:
{
"role": "tool",
"tool_call_id": "call_abc123",
"content": [
{
"type": "text",
"text": "{\"url\": \"https://example.com\", \"status\": \"completed\"}"
},
{
"type": "input_image",
"image_url": "data:image/png;base64,..."
}
]
}
Environment Mapping
| LiteLLM Input | Gemini API Value |
|---|---|
"browser" | ENVIRONMENT_BROWSER |
"unspecified" | ENVIRONMENT_UNSPECIFIED |
ENVIRONMENT_BROWSER | ENVIRONMENT_BROWSER (passed through) |
ENVIRONMENT_UNSPECIFIED | ENVIRONMENT_UNSPECIFIED (passed through) |
Thought Signatures
Thought signatures are encrypted representations of the model's internal reasoning process for a given turn in a conversation. By passing thought signatures back to the model in subsequent requests, you provide it with the context of its previous thoughts, allowing it to build upon its reasoning and maintain a coherent line of inquiry.
Thought signatures are particularly important for multi-turn function calling scenarios where the model needs to maintain context across multiple tool invocations.
How Thought Signatures Work
- Function calls with signatures: When Gemini returns a function call, it includes a
thought_signaturein the response - Preservation: LiteLLM automatically extracts and stores thought signatures in
provider_specific_fieldsof tool calls - Return in conversation history: When you include the assistant's message with tool calls in subsequent requests, LiteLLM automatically preserves and returns the thought signatures to Gemini
- Parallel function calls: Only the first function call in a parallel set has a thought signature
- Sequential function calls: Each function call in a multi-step sequence has its own signature
Enabling Thought Signatures
To enable thought signatures, you need to enable thinking/reasoning:
- SDK
- PROXY
from litellm import completion
response = completion(
model="gemini/gemini-2.5-flash",
messages=[{"role": "user", "content": "What's the weather in Tokyo?"}],
tools=[...],
reasoning_effort="low", # Enable thinking to get thought signatures
)
curl http://localhost:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234" \
-d '{
"model": "gemini-2.5-flash",
"messages": [{"role": "user", "content": "What'\''s the weather in Tokyo?"}],
"tools": [...],
"reasoning_effort": "low"
}'
Multi-Turn Function Calling with Thought Signatures
When building conversation history for multi-turn function calling, you must include the thought signatures from previous responses. LiteLLM handles this automatically when you append the full assistant message to your conversation history.
- OpenAI Client
- cURL
from openai import OpenAI
import json
client = OpenAI(api_key="sk-1234", base_url="http://localhost:4000")
def get_current_temperature(location: str) -> dict:
"""Gets the current weather temperature for a given location."""
return {"temperature": 30, "unit": "celsius"}
def set_thermostat_temperature(temperature: int) -> dict:
"""Sets the thermostat to a desired temperature."""
return {"status": "success"}
get_weather_declaration = {
"name": "get_current_temperature",
"description": "Gets the current weather temperature for a given location.",
"parameters": {
"type": "object",
"properties": {"location": {"type": "string"}},
"required": ["location"],
},
}
set_thermostat_declaration = {
"name": "set_thermostat_temperature",
"description": "Sets the thermostat to a desired temperature.",
"parameters": {
"type": "object",
"properties": {"temperature": {"type": "integer"}},
"required": ["temperature"],
},
}
# Initial request
messages = [
{"role": "user", "content": "If it's too hot or too cold in London, set the thermostat to a comfortable level."}
]
response = client.chat.completions.create(
model="gemini-2.5-flash",
messages=messages,
tools=[get_weather_declaration, set_thermostat_declaration],
reasoning_effort="low"
)
# Append the assistant's message (includes thought signatures automatically)
messages.append(response.choices[0].message)
# Execute tool calls and append results
for tool_call in response.choices[0].message.tool_calls:
if tool_call.function.name == "get_current_temperature":
result = get_current_temperature(**json.loads(tool_call.function.arguments))
messages.append({
"role": "tool",
"content": json.dumps(result),
"tool_call_id": tool_call.id
})
# Second request - thought signatures are automatically preserved
response2 = client.chat.completions.create(
model="gemini-2.5-flash",
messages=messages,
tools=[get_weather_declaration, set_thermostat_declaration],
reasoning_effort="low"
)
print(response2.choices[0].message.content)
# Step 1: Initial request
curl --location 'http://localhost:4000/v1/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer sk-1234' \
--data '{
"model": "gemini-2.5-flash",
"messages": [
{
"role": "user",
"content": "If it'\''s too hot or too cold in London, set the thermostat to a comfortable level."
}
],
"tools": [
{
"type": "function",
"function": {
"name": "get_current_temperature",
"description": "Gets the current weather temperature for a given location.",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string"}
},
"required": ["location"]
}
}
},
{
"type": "function",
"function": {
"name": "set_thermostat_temperature",
"description": "Sets the thermostat to a desired temperature.",
"parameters": {
"type": "object",
"properties": {
"temperature": {"type": "integer"}
},
"required": ["temperature"]
}
}
}
],
"tool_choice": "auto",
"reasoning_effort": "low"
}'
The response will include tool calls with thought signatures in provider_specific_fields:
{
"choices": [{
"message": {
"role": "assistant",
"tool_calls": [{
"id": "call_abc123",
"type": "function",
"function": {
"name": "get_current_temperature",
"arguments": "{\"location\": \"London\"}"
},
"index": 0,
"provider_specific_fields": {
"thought_signature": "CpcHAdHtim9+q4rstcbvQC0ic4x1/vqQlCJWgE+UZ6dTLYGHMMBkF/AxqL5UmP6SY46uYC8t4BTFiXG5zkw6EMJ...=="
}
}]
}
}]
}
# Step 2: Follow-up request with tool response
# Include the assistant message from Step 1 (with thought signatures in provider_specific_fields)
curl --location 'http://localhost:4000/v1/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer sk-1234' \
--data '{
"model": "gemini-2.5-flash",
"messages": [
{
"role": "user",
"content": "If it'\''s too hot or too cold in London, set the thermostat to a comfortable level."
},
{
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "call_c130b9f8c2c042e9b65e39a88245",
"type": "function",
"function": {
"name": "get_current_temperature",
"arguments": "{\"location\": \"London\"}"
},
"index": 0,
"provider_specific_fields": {
"thought_signature": "CpcHAdHtim9+q4rstcbvQC0ic4x1/vqQlCJWgE+UZ6dTLYGHMMBkF/AxqL5UmP6SY46uYC8t4BTFiXG5zkw6EMJ...=="
}
}
]
},
{
"role": "tool",
"content": "{\"temperature\": 30, \"unit\": \"celsius\"}",
"tool_call_id": "call_c130b9f8c2c042e9b65e39a88245"
}
],
"tools": [
{
"type": "function",
"function": {
"name": "get_current_temperature",
"description": "Gets the current weather temperature for a given location.",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string"}
},
"required": ["location"]
}
}
},
{
"type": "function",
"function": {
"name": "set_thermostat_temperature",
"description": "Sets the thermostat to a desired temperature.",
"parameters": {
"type": "object",
"properties": {
"temperature": {"type": "integer"}
},
"required": ["temperature"]
}
}
}
],
"tool_choice": "auto",
"reasoning_effort": "low"
}'
Important Notes
-
Automatic Handling: LiteLLM automatically extracts thought signatures from Gemini responses and preserves them when you include assistant messages in conversation history. You don't need to manually extract or manage them.
-
Parallel Function Calls: When the model makes parallel function calls, only the first function call will have a thought signature. Subsequent parallel calls won't have signatures.
-
Sequential Function Calls: In multi-step function calling scenarios, each step's first function call will have its own thought signature that must be preserved.
-
Required for Context: Thought signatures are essential for maintaining reasoning context across multi-turn conversations with function calling. Without them, the model may lose context of its previous reasoning.
-
Format: Thought signatures are stored in
provider_specific_fields.thought_signatureof tool calls in the response, and are automatically included when you append the assistant message to your conversation history. -
Chat Completions Clients: With chat completions clients where you cannot control whether or not the previous assistant message is included as-is (ex langchain's ChatOpenAI), LiteLLM also preserves the thought signature by appending it to the tool call id (
call_123__thought__<thought-signature>) and extracting it back out before sending the outbound request to Gemini.
JSON Mode
- SDK
- PROXY
from litellm import completion
import json
import os
os.environ['GEMINI_API_KEY'] = ""
messages = [
{
"role": "user",
"content": "List 5 popular cookie recipes."
}
]
completion(
model="gemini/gemini-1.5-pro",
messages=messages,
response_format={"type": "json_object"} # 👈 KEY CHANGE
)
print(json.loads(completion.choices[0].message.content))
- Add model to config.yaml
model_list:
- model_name: gemini-pro
litellm_params:
model: gemini/gemini-1.5-pro
api_key: os.environ/GEMINI_API_KEY
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-d '{
"model": "gemini-pro",
"messages": [
{"role": "user", "content": "List 5 popular cookie recipes."}
],
"response_format": {"type": "json_object"}
}
'
Gemini-Pro-Vision
LiteLLM Supports the following image types passed in url
- Images with direct links - https://storage.googleapis.com/github-repo/img/gemini/intro/landmark3.jpg
- Image in local storage - ./localimage.jpeg
Media Resolution Control (Images & Videos)
LiteLLM supports OpenAI's detail parameter for specifying the image resolution when using Gemini models. The behavior differs between Gemini versions:
| Gemini Version | Resolution Control | Behavior |
|---|---|---|
| Gemini 3+ | Per-part | Each image/video can have its own detail setting |
| Gemini 2.x (2.0, 2.5) | Global | The highest detail from all images is applied globally via mediaResolution in generationConfig |
Supported detail values:
"low"- Maps toMEDIA_RESOLUTION_LOW(280 tokens for images, 70 tokens per frame for videos)"medium"- Maps toMEDIA_RESOLUTION_MEDIUM"high"- Maps toMEDIA_RESOLUTION_HIGH(1120 tokens for images)"ultra_high"- Maps toMEDIA_RESOLUTION_ULTRA_HIGH"auto"orNone- Model decides optimal resolution (nomedia_resolutionset)
Usage Examples:
- Images
- Videos with Files
from litellm import completion
messages = [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://example.com/chart.png",
"detail": "high" # High resolution for detailed chart analysis
}
},
{
"type": "text",
"text": "Analyze this chart"
},
{
"type": "image_url",
"image_url": {
"url": "https://example.com/icon.png",
"detail": "low" # Low resolution for simple icon
}
}
]
}
]
# Works with both Gemini 2.x and 3+
response = completion(
model="gemini/gemini-2.5-flash", # or gemini-3-pro-preview
messages=messages,
)
from litellm import completion
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Analyze this video"
},
{
"type": "file",
"file": {
"file_id": "gs://my-bucket/video.mp4",
"format": "video/mp4",
"detail": "high" # High resolution for detailed video analysis
}
}
]
}
]
response = completion(
model="gemini/gemini-3-pro-preview",
messages=messages,
)
Gemini 3+ Per-Part Resolution: Each image or video can have its own detail setting, allowing mixed-resolution requests (e.g., a high-res chart alongside a low-res icon). This works with both image_url and file content types.
Gemini 2.x Global Resolution: When multiple images have different detail values, LiteLLM uses the highest resolution found and applies it globally via mediaResolution in generationConfig (e.g., if one image has "low" and another has "high", all images will use "high").
Video Metadata Control
For Gemini 3+ models, LiteLLM supports fine-grained video processing control through the video_metadata field. This allows you to specify frame extraction rates and time ranges for video analysis.
Supported video_metadata parameters:
| Parameter | Type | Description | Example |
|---|---|---|---|
fps | Number | Frame extraction rate (frames per second) | 5 |
start_offset | String | Start time for video clip processing | "10s" |
end_offset | String | End time for video clip processing | "60s" |
Field Name Conversion: LiteLLM automatically converts snake_case field names to camelCase for the Gemini API:
start_offset→startOffsetend_offset→endOffsetfpsremains unchanged
- Gemini 3+ Only: This feature is only available for Gemini 3.0 and newer models
- Video Files Recommended: While
video_metadatais designed for video files, error handling for other media types is delegated to the Vertex AI API - File Formats Supported: Works with
gs://,https://, and base64-encoded video files
Usage Examples:
- Basic Video Metadata
- Combined with Detail
- PROXY
from litellm import completion
response = completion(
model="gemini/gemini-3-pro-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Analyze this video clip"},
{
"type": "file",
"file": {
"file_id": "gs://my-bucket/video.mp4",
"format": "video/mp4",
"video_metadata": {
"fps": 5, # Extract 5 frames per second
"start_offset": "10s", # Start from 10 seconds
"end_offset": "60s" # End at 60 seconds
}
}
}
]
}
]
)
print(response.choices[0].message.content)
from litellm import completion
response = completion(
model="gemini/gemini-3-pro-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Provide detailed analysis of this video segment"},
{
"type": "file",
"file": {
"file_id": "https://example.com/presentation.mp4",
"format": "video/mp4",
"detail": "high", # High resolution for detailed analysis
"video_metadata": {
"fps": 10, # Extract 10 frames per second
"start_offset": "30s", # Start from 30 seconds
"end_offset": "90s" # End at 90 seconds
}
}
}
]
}
]
)
print(response.choices[0].message.content)
- Setup config.yaml
model_list:
- model_name: gemini-3-pro
litellm_params:
model: gemini/gemini-3-pro-preview
api_key: os.environ/GEMINI_API_KEY
- Start proxy
litellm --config /path/to/config.yaml
- Make request
curl http://0.0.0.0:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR-LITELLM-KEY>" \
-d '{
"model": "gemini-3-pro",
"messages": [
{
"role": "user",
"content": [
{"type": "text", "text": "Analyze this video clip"},
{
"type": "file",
"file": {
"file_id": "gs://my-bucket/video.mp4",
"format": "video/mp4",
"detail": "high",
"video_metadata": {
"fps": 5,
"start_offset": "10s",
"end_offset": "60s"
}
}
}
]
}
]
}'
Sample Usage
import os
import litellm
from dotenv import load_dotenv
# Load the environment variables from .env file
load_dotenv()
os.environ["GEMINI_API_KEY"] = os.getenv('GEMINI_API_KEY')
prompt = 'Describe the image in a few sentences.'
# Note: You can pass here the URL or Path of image directly.
image_url = 'https://storage.googleapis.com/github-repo/img/gemini/intro/landmark3.jpg'
# Create the messages payload according to the documentation
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
},
{
"type": "image_url",
"image_url": {"url": image_url}
}
]
}
]
# Make the API call to Gemini model
response = litellm.completion(
model="gemini/gemini-pro-vision",
messages=messages,
)
# Extract the response content
content = response.get('choices', [{}])[0].get('message', {}).get('content')
# Print the result
print(content)
gemini-robotics-er-1.5-preview Usage
from litellm import api_base
from openai import OpenAI
import os
import base64
client = OpenAI(base_url="http://0.0.0.0:4000", api_key="sk-12345")
base64_image = base64.b64encode(open("closeup-object-on-table-many-260nw-1216144471.webp", "rb").read()).decode()
import json
import re
tools = [{"codeExecution": {}}]
response = client.chat.completions.create(
model="gemini/gemini-robotics-er-1.5-preview",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Point to no more than 10 items in the image. The label returned should be an identifying name for the object detected. The answer should follow the json format: [{\"point\": [y, x], \"label\": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000."
},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"}
}
]
}
],
tools=tools
)
# Extract JSON from markdown code block if present
content = response.choices[0].message.content
# Look for triple-backtick JSON block
match = re.search(r'```json\s*(.*?)\s*```', content, re.DOTALL)
if match:
json_str = match.group(1)
else:
json_str = content
try:
data = json.loads(json_str)
print(json.dumps(data, indent=2))
except Exception as e:
print("Error parsing response as JSON:", e)
print("Response content:", content)
Usage - PDF / Videos / etc. Files
Inline Data (e.g. audio stream)
LiteLLM follows the OpenAI format and accepts sending inline data as an encoded base64 string.
The format to follow is
data:<mime_type>;base64,<encoded_data>
** LITELLM CALL **
import litellm
from pathlib import Path
import base64
import os
os.environ["GEMINI_API_KEY"] = ""
litellm.set_verbose = True # 👈 See Raw call
audio_bytes = Path("speech_vertex.mp3").read_bytes()
encoded_data = base64.b64encode(audio_bytes).decode("utf-8")
print("Audio Bytes = {}".format(audio_bytes))
model = "gemini/gemini-1.5-flash"
response = litellm.completion(
model=model,
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Please summarize the audio."},
{
"type": "file",
"file": {
"file_data": "data:audio/mp3;base64,{}".format(encoded_data), # 👈 SET MIME_TYPE + DATA
}
},
],
}
],
)
** Equivalent GOOGLE API CALL **
# Initialize a Gemini model appropriate for your use case.
model = genai.GenerativeModel('models/gemini-1.5-flash')
# Create the prompt.
prompt = "Please summarize the audio."
# Load the samplesmall.mp3 file into a Python Blob object containing the audio
# file's bytes and then pass the prompt and the audio to Gemini.
response = model.generate_content([
prompt,
{
"mime_type": "audio/mp3",
"data": pathlib.Path('samplesmall.mp3').read_bytes()
}
])
# Output Gemini's response to the prompt and the inline audio.
print(response.text)
https:// file
import litellm
import os
os.environ["GEMINI_API_KEY"] = ""
litellm.set_verbose = True # 👈 See Raw call
model = "gemini/gemini-1.5-flash"
response = litellm.completion(
model=model,
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Please summarize the file."},
{
"type": "file",
"file": {
"file_id": "https://storage...", # 👈 SET THE IMG URL
"format": "application/pdf" # OPTIONAL
}
},
],
}
],
)
gs:// file
import litellm
import os
os.environ["GEMINI_API_KEY"] = ""
litellm.set_verbose = True # 👈 See Raw call
model = "gemini/gemini-1.5-flash"
response = litellm.completion(
model=model,
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Please summarize the file."},
{
"type": "file",
"file": {
"file_id": "gs://storage...", # 👈 SET THE IMG URL
"format": "application/pdf" # OPTIONAL
}
},
],
}
],
)
Chat Models
We support ALL Gemini models, just set model=gemini/<any-model-on-gemini> as a prefix when sending litellm requests
| Model Name | Function Call | Required OS Variables |
|---|---|---|
| gemini-pro | completion(model='gemini/gemini-pro', messages) | os.environ['GEMINI_API_KEY'] |
| gemini-1.5-pro-latest | completion(model='gemini/gemini-1.5-pro-latest', messages) | os.environ['GEMINI_API_KEY'] |
| gemini-2.0-flash | completion(model='gemini/gemini-2.0-flash', messages) | os.environ['GEMINI_API_KEY'] |
| gemini-2.0-flash-exp | completion(model='gemini/gemini-2.0-flash-exp', messages) | os.environ['GEMINI_API_KEY'] |
| gemini-2.0-flash-lite-preview-02-05 | completion(model='gemini/gemini-2.0-flash-lite-preview-02-05', messages) | os.environ['GEMINI_API_KEY'] |
| gemini-2.5-flash-preview-09-2025 | completion(model='gemini/gemini-2.5-flash-preview-09-2025', messages) | os.environ['GEMINI_API_KEY'] |
| gemini-2.5-flash-lite-preview-09-2025 | completion(model='gemini/gemini-2.5-flash-lite-preview-09-2025', messages) | os.environ['GEMINI_API_KEY'] |
| gemini-3.1-flash-lite-preview | completion(model='gemini/gemini-3.1-flash-lite-preview', messages) | os.environ['GEMINI_API_KEY'] |
| gemini-flash-latest | completion(model='gemini/gemini-flash-latest', messages) | os.environ['GEMINI_API_KEY'] |
| gemini-flash-lite-latest | completion(model='gemini/gemini-flash-lite-latest', messages) | os.environ['GEMINI_API_KEY'] |
Context Caching
Use Google AI Studio context caching is supported by
{
{
"role": "system",
"content": ...,
"cache_control": {"type": "ephemeral"} # 👈 KEY CHANGE
},
...
}
in your message content block.
Custom TTL Support
You can now specify a custom Time-To-Live (TTL) for your cached content using the ttl parameter:
{
{
"role": "system",
"content": ...,
"cache_control": {
"type": "ephemeral",
"ttl": "3600s" # 👈 Cache for 1 hour
}
},
...
}
TTL Format Requirements:
- Must be a string ending with 's' for seconds
- Must contain a positive number (can be decimal)
- Examples:
"3600s"(1 hour),"7200s"(2 hours),"1800s"(30 minutes),"1.5s"(1.5 seconds)
TTL Behavior:
- If multiple cached messages have different TTLs, the first valid TTL encountered will be used
- Invalid TTL formats are ignored and the cache will use Google's default expiration time
- If no TTL is specified, Google's default cache expiration (approximately 1 hour) applies
Architecture Diagram
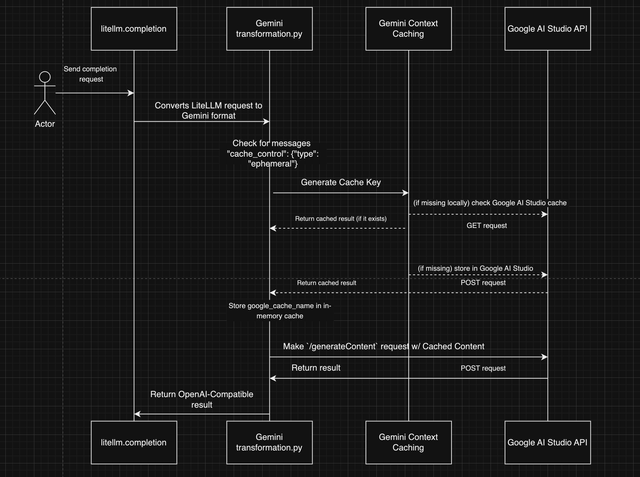
Notes:
-
Gemini Context Caching only allows 1 block of continuous messages to be cached.
-
If multiple non-continuous blocks contain
cache_control- the first continuous block will be used. (sent to/cachedContentin the Gemini format) -
The raw request to Gemini's
/generateContentendpoint looks like this:
curl -X POST "https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash-001:generateContent?key=$GOOGLE_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"contents": [
{
"parts":[{
"text": "Please summarize this transcript"
}],
"role": "user"
},
],
"cachedContent": "'$CACHE_NAME'"
}'
Example Usage
- SDK
- SDK with Custom TTL
- PROXY
from litellm import completion
for _ in range(2):
resp = completion(
model="gemini/gemini-1.5-pro",
messages=[
# System Message
{
"role": "system",
"content": [
{
"type": "text",
"text": "Here is the full text of a complex legal agreement" * 4000,
"cache_control": {"type": "ephemeral"}, # 👈 KEY CHANGE
}
],
},
# marked for caching with the cache_control parameter, so that this checkpoint can read from the previous cache.
{
"role": "user",
"content": [
{
"type": "text",
"text": "What are the key terms and conditions in this agreement?",
"cache_control": {"type": "ephemeral"},
}
],
}]
)
print(resp.usage) # 👈 2nd usage block will be less, since cached tokens used
from litellm import completion
# Cache for 2 hours (7200 seconds)
resp = completion(
model="gemini/gemini-1.5-pro",
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "Here is the full text of a complex legal agreement" * 4000,
"cache_control": {
"type": "ephemeral",
"ttl": "7200s" # 👈 Cache for 2 hours
},
}
],
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "What are the key terms and conditions in this agreement?",
"cache_control": {
"type": "ephemeral",
"ttl": "3600s" # 👈 This TTL will be ignored (first one is used)
},
}
],
}
]
)
print(resp.usage)
- Setup config.yaml
model_list:
- model_name: gemini-1.5-pro
litellm_params:
model: gemini/gemini-1.5-pro
api_key: os.environ/GEMINI_API_KEY
- Start proxy
litellm --config /path/to/config.yaml
- Test it!
See Langchain, OpenAI JS, Llamaindex, etc. examples
- Curl
- Curl with Custom TTL
- OpenAI Python SDK
- OpenAI Python SDK with TTL
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data '{
"model": "gemini-1.5-pro",
"messages": [
# System Message
{
"role": "system",
"content": [
{
"type": "text",
"text": "Here is the full text of a complex legal agreement" * 4000,
"cache_control": {"type": "ephemeral"}, # 👈 KEY CHANGE
}
],
},
# marked for caching with the cache_control parameter, so that this checkpoint can read from the previous cache.
{
"role": "user",
"content": [
{
"type": "text",
"text": "What are the key terms and conditions in this agreement?",
"cache_control": {"type": "ephemeral"},
}
],
}],
}'
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data '{
"model": "gemini-1.5-pro",
"messages": [
{
"role": "system",
"content": [
{
"type": "text",
"text": "Here is the full text of a complex legal agreement" * 4000,
"cache_control": {
"type": "ephemeral",
"ttl": "7200s"
}
}
]
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "What are the key terms and conditions in this agreement?",
"cache_control": {
"type": "ephemeral",
"ttl": "3600s"
}
}
]
}
]
}'
import openai
client = openai.AsyncOpenAI(
api_key="anything", # litellm proxy api key
base_url="http://0.0.0.0:4000" # litellm proxy base url
)
response = await client.chat.completions.create(
model="gemini-1.5-pro",
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "Here is the full text of a complex legal agreement" * 4000,
"cache_control": {"type": "ephemeral"}, # 👈 KEY CHANGE
}
],
},
{
"role": "user",
"content": "what are the key terms and conditions in this agreement?",
},
]
)
import openai
client = openai.AsyncOpenAI(
api_key="anything", # litellm proxy api key
base_url="http://0.0.0.0:4000" # litellm proxy base url
)
response = await client.chat.completions.create(
model="gemini-1.5-pro",
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "Here is the full text of a complex legal agreement" * 4000,
"cache_control": {
"type": "ephemeral",
"ttl": "7200s" # Cache for 2 hours
}
}
],
},
{
"role": "user",
"content": "what are the key terms and conditions in this agreement?",
},
]
)
Image Generation
- SDK
- PROXY
from litellm import completion
response = completion(
model="gemini/gemini-2.0-flash-exp-image-generation",
messages=[{"role": "user", "content": "Generate an image of a cat"}],
modalities=["image", "text"],
)
assert response.choices[0].message.content is not None # "data:image/png;base64,e4rr.."
- Setup config.yaml
model_list:
- model_name: gemini-2.0-flash-exp-image-generation
litellm_params:
model: gemini/gemini-2.0-flash-exp-image-generation
api_key: os.environ/GEMINI_API_KEY
- Start proxy
litellm --config /path/to/config.yaml
- Test it!
curl -L -X POST 'http://localhost:4000/v1/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-d '{
"model": "gemini-2.0-flash-exp-image-generation",
"messages": [{"role": "user", "content": "Generate an image of a cat"}],
"modalities": ["image", "text"]
}'
Image Generation Pricing
Gemini image generation models (like gemini-3-pro-image-preview) return image_tokens in the response usage. These tokens are priced differently from text tokens:
| Token Type | Price per 1M tokens | Price per token |
|---|---|---|
| Text output | $12 | $0.000012 |
| Image output | $120 | $0.00012 |
The number of image tokens depends on the output resolution:
| Resolution | Tokens per image | Cost per image |
|---|---|---|
| 1K-2K (1024x1024 to 2048x2048) | 1,120 | $0.134 |
| 4K (4096x4096) | 2,000 | $0.24 |
LiteLLM automatically calculates costs using output_cost_per_image_token from the model pricing configuration.
Example response usage:
{
"completion_tokens_details": {
"reasoning_tokens": 225,
"text_tokens": 0,
"image_tokens": 1120
}
}
For more details, see Google's Gemini pricing documentation.