v1.72.2-stable


Deploy this version
- Docker
- Pip
docker run
-e STORE_MODEL_IN_DB=True
-p 4000:4000
docker.litellm.ai/berriai/litellm:main-v1.72.2-stable
pip install litellm==1.72.2.post1
TLDR
- Why Upgrade
- Performance Improvements for /v1/messages: For this endpoint LiteLLM Proxy overhead is now down to 50ms at 250 RPS.
- Accurate Rate Limiting: Multi-instance rate limiting now tracks rate limits across keys, models, teams, and users with 0 spillover.
- Audit Logs on UI: Track when Keys, Teams, and Models were deleted by viewing Audit Logs on the LiteLLM UI.
- /v1/messages all models support: You can now use all LiteLLM models (
gpt-4.1,o1-pro,gemini-2.5-pro) with /v1/messages API. - Anthropic MCP: Use remote MCP Servers with Anthropic Models.
- Who Should Read
- Teams using
/v1/messagesAPI (Claude Code) - Proxy Admins using LiteLLM Virtual Keys and setting rate limits
- Teams using
- Risk of Upgrade
- Medium
- Upgraded
ddtrace==3.8.0, if you use DataDog tracing this is a medium level risk. We recommend monitoring logs for any issues.
- Upgraded
- Medium
/v1/messages Performance Improvements

This release brings significant performance improvements to the /v1/messages API on LiteLLM.
For this endpoint LiteLLM Proxy overhead latency is now down to 50ms, and each instance can handle 250 RPS. We validated these improvements through load testing with payloads containing over 1,000 streaming chunks.
This is great for real time use cases with large requests (eg. multi turn conversations, Claude Code, etc.).
Multi-Instance Rate Limiting Improvements
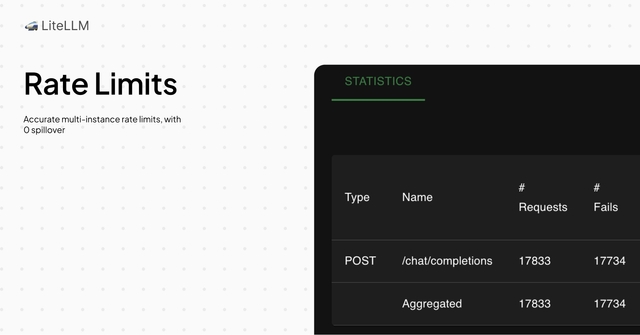
LiteLLM now accurately tracks rate limits across keys, models, teams, and users with 0 spillover.
This is a significant improvement over the previous version, which faced issues with leakage and spillover in high traffic, multi-instance setups.
Key Changes:
- Redis is now part of the rate limit check, instead of being a background sync. This ensures accuracy and reduces read/write operations during low activity.
- LiteLLM now uses Lua scripts to ensure all checks are atomic.
- In-memory caching uses Redis values. This prevents drift, and reduces Redis queries once objects are over their limit.
These changes are currently behind the feature flag - EXPERIMENTAL_ENABLE_MULTI_INSTANCE_RATE_LIMITING=True. We plan to GA this in our next release - subject to feedback.
Audit Logs on UI
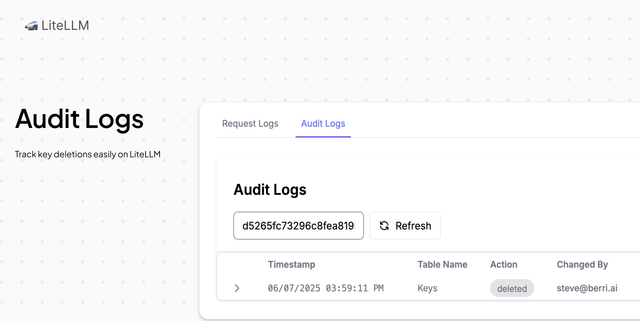
This release introduces support for viewing audit logs in the UI. As a Proxy Admin, you can now check if and when a key was deleted, along with who performed the action.
LiteLLM tracks changes to the following entities and actions:
- Entities: Keys, Teams, Users, Models
- Actions: Create, Update, Delete, Regenerate
New Models / Updated Models
Newly Added Models
| Provider | Model | Context Window | Input ($/1M tokens) | Output ($/1M tokens) |
|---|---|---|---|---|
| Anthropic | claude-4-opus-20250514 | 200K | $15.00 | $75.00 |
| Anthropic | claude-4-sonnet-20250514 | 200K | $3.00 | $15.00 |
| VertexAI, Google AI Studio | gemini-2.5-pro-preview-06-05 | 1M | $1.25 | $10.00 |
| OpenAI | codex-mini-latest | 200K | $1.50 | $6.00 |
| Cerebras | qwen-3-32b | 128K | $0.40 | $0.80 |
| SambaNova | DeepSeek-R1 | 32K | $5.00 | $7.00 |
| SambaNova | DeepSeek-R1-Distill-Llama-70B | 131K | $0.70 | $1.40 |
Model Updates
- Anthropic
- Google AI Studio
- OpenAI
- Cost tracking for
codex-mini-latest- PR
- Cost tracking for
- Vertex AI
- Cerebras
- Cerebras/qwen-3-32b model pricing and context window - PR
- HuggingFace
- Fixed embeddings using non-default
input_type- PR
- Fixed embeddings using non-default
- DataRobot
- New provider integration for enterprise AI workflows - PR
- DeepSeek
LLM API Endpoints
- Images API
- Azure endpoint support for image endpoints - PR
- Anthropic Messages API
- Embeddings API
- Rerank API
Spend Tracking
- Added token tracking for anthropic batch calls via /anthropic passthrough route- PR
Management Endpoints / UI
- SSO/Authentication
- Teams
- SCIM
- Fixed SCIM running patch operation case sensitivity - PR
- General
Logging / Guardrails Integrations
Logging
- S3
- Async + Batched S3 Logging for improved performance - PR
- DataDog
- Prometheus
- Pass custom metadata labels in litellm_total_token metrics - PR
- GCS
- Update GCSBucketBase to handle GSM project ID if passed - PR
Guardrails
Performance / Reliability Improvements
- Performance Optimizations
- Don't run auth on /health/liveliness endpoints - PR
- Don't create 1 task for every hanging request alert - PR
- Add debugging endpoint to track active /asyncio-tasks - PR
- Make batch size for maximum retention in spend logs controllable - PR
- Expose flag to disable token counter - PR
- Support pipeline redis lpop for older redis versions - PR
Bug Fixes
- LLM API Fixes
- Anthropic: Fix regression when passing file url's to the 'file_id' parameter - PR
- Vertex AI: Fix Vertex AI any_of issues for Description and Default. - PR
- Fix transcription model name mapping - PR
- Image Generation: Fix None values in usage field for gpt-image-1 model responses - PR
- Responses API: Fix _transform_responses_api_content_to_chat_completion_content doesn't support file content type - PR
- Fireworks AI: Fix rate limit exception mapping - detect "rate limit" text in error messages - PR
- Spend Tracking/Budgets
- Respect user_header_name property for budget selection and user identification - PR
- MCP Server
- Remove duplicate server_id MCP config servers - PR
- Function Calling
- supports_function_calling works with llm_proxy models - PR
- Knowledge Base
- Fixed Knowledge Base Call returning error - PR
New Contributors
- @mjnitz02 made their first contribution in #10385
- @hagan made their first contribution in #10479
- @wwells made their first contribution in #11409
- @likweitan made their first contribution in #11400
- @raz-alon made their first contribution in #10102
- @jtsai-quid made their first contribution in #11394
- @tmbo made their first contribution in #11362
- @wangsha made their first contribution in #11351
- @seankwalker made their first contribution in #11452
- @pazevedo-hyland made their first contribution in #11381
- @cainiaoit made their first contribution in #11438
- @vuanhtu52 made their first contribution in #11508
Demo Instance
Here's a Demo Instance to test changes:
- Instance: https://demo.litellm.ai/
- Login Credentials:
- Username: admin
- Password: sk-1234