Setting Team Budgets
Pre-Requisites
- You must set up a Postgres database (e.g. Supabase, Neon, etc.)
Default Budget for Auto-Generated JWT Teams
When using JWT authentication with team_id_upsert: true, you can automatically assign a default budget to any newly created team.
This is configured in default_team_settings in your config.yaml.
Example:
# in your config.yaml
litellm_jwtauth:
team_id_upsert: true
team_id_jwt_field: "team_id"
# ... other jwt settings
litellm_settings:
default_team_settings:
- team_id: "default-settings"
max_budget: 100.0
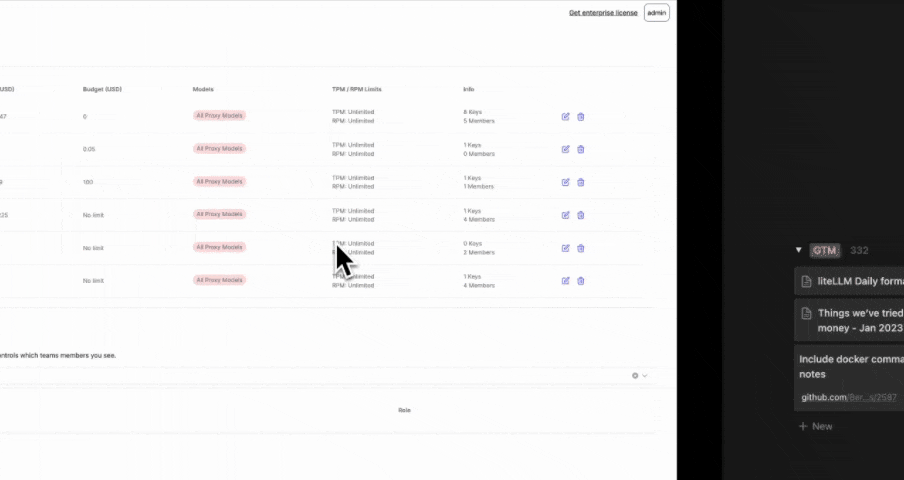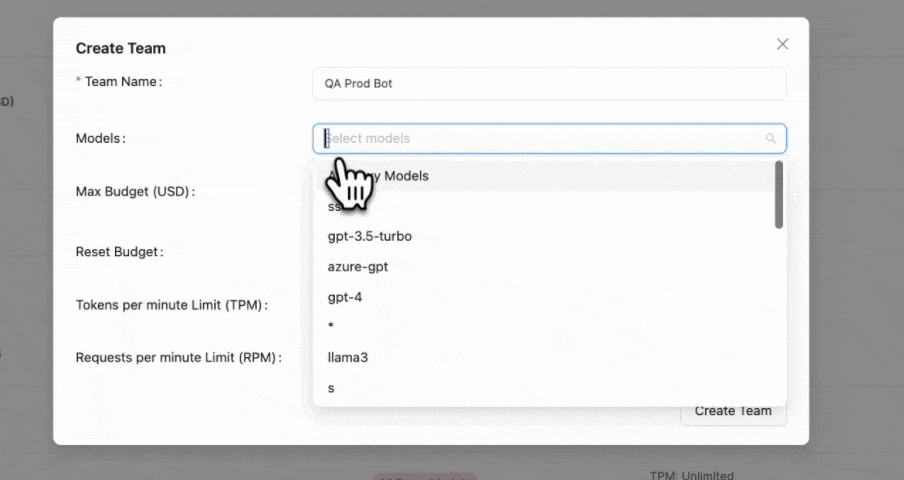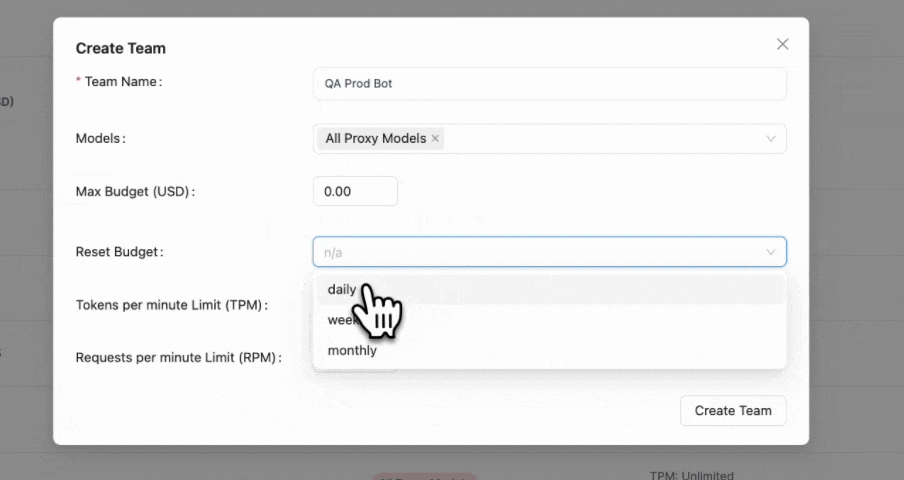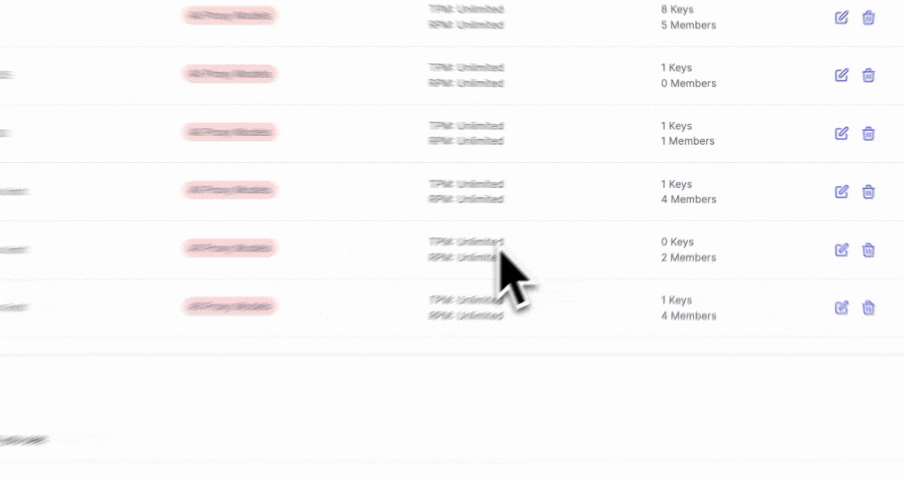
Track spend, set budgets for your Internal Team
Setting Monthly Team Budgets
1. Create a team
- Set
max_budget=000000001($ value the team is allowed to spend) - Set
budget_duration="1d"(How frequently the budget should update)
- API
- Admin UI
Create a new team and set max_budget and budget_duration
curl -X POST 'http://0.0.0.0:4000/team/new' \
-H 'Authorization: Bearer sk-1234' \
-H 'Content-Type: application/json' \
-d '{
"team_alias": "QA Prod Bot",
"max_budget": 0.000000001,
"budget_duration": "1d"
}'
Response
{
"team_alias": "QA Prod Bot",
"team_id": "de35b29e-6ca8-4f47-b804-2b79d07aa99a",
"max_budget": 0.0001,
"budget_duration": "1d",
"budget_reset_at": "2024-06-14T22:48:36.594000Z"
}
Possible values for budget_duration
budget_duration | When Budget will reset |
|---|---|
budget_duration="1s" | every 1 second |
budget_duration="1m" | every 1 min |
budget_duration="1h" | every 1 hour |
budget_duration="1d" | every 1 day |
budget_duration="30d" | every 1 month |
2. Create a key for the team
Create a key for Team=QA Prod Bot and team_id="de35b29e-6ca8-4f47-b804-2b79d07aa99a" from Step 1
- API
- Admin UI
💡 The Budget for Team="QA Prod Bot" budget will apply to this team
curl -X POST 'http://0.0.0.0:4000/key/generate' \
-H 'Authorization: Bearer sk-1234' \
-H 'Content-Type: application/json' \
-d '{"team_id": "de35b29e-6ca8-4f47-b804-2b79d07aa99a"}'
Response
{"team_id":"de35b29e-6ca8-4f47-b804-2b79d07aa99a", "key":"sk-5qtncoYjzRcxMM4bDRktNQ"}

3. Test It
Use the key from step 2 and run this Request twice
- API
- Admin UI
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Authorization: Bearer sk-mso-JSykEGri86KyOvgxBw' \
-H 'Content-Type: application/json' \
-d ' {
"model": "llama3",
"messages": [
{
"role": "user",
"content": "hi"
}
]
}'
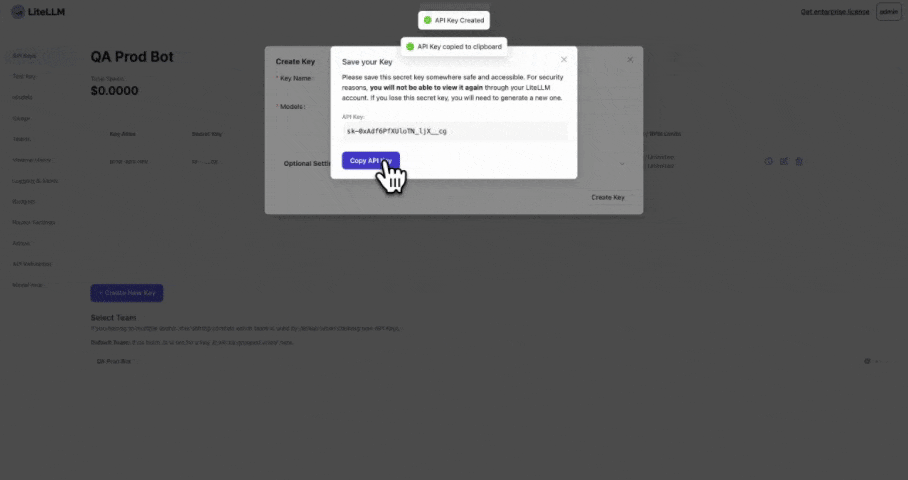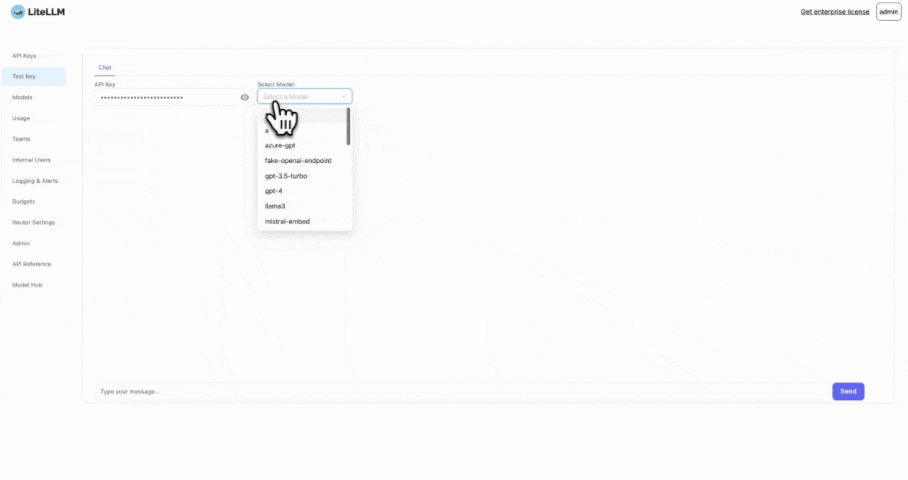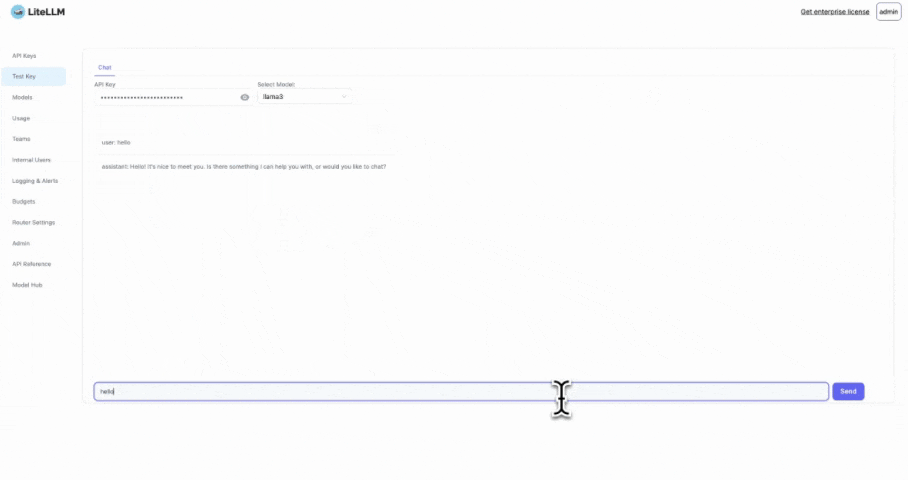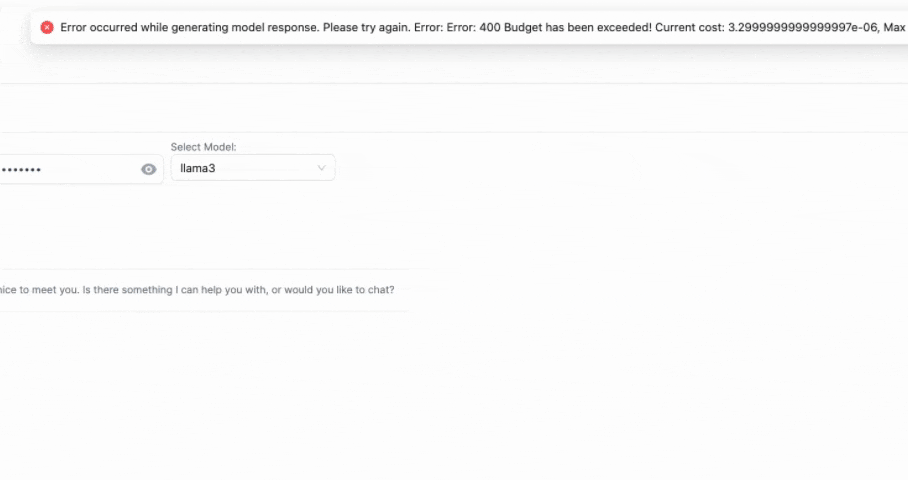
On the 2nd response - expect to see the following exception
{
"error": {
"message": "Budget has been exceeded! Current cost: 3.5e-06, Max budget: 1e-09",
"type": "auth_error",
"param": null,
"code": 400
}
}
Advanced
Prometheus metrics for remaining_budget
More info about Prometheus metrics here
You'll need the following in your proxy config.yaml
litellm_settings:
success_callback: ["prometheus"]
failure_callback: ["prometheus"]
Expect to see this metric on prometheus to track the Remaining Budget for the team
litellm_remaining_team_budget_metric{team_alias="QA Prod Bot",team_id="de35b29e-6ca8-4f47-b804-2b79d07aa99a"} 9.699999999999992e-06
See Also
- Per-model TPM/RPM for teams - Set rate limits per model for all keys in a team