Health Checks
Two things consume the proxy's health state. Your orchestrator (Kubernetes, a load balancer, an uptime monitor) polls lightweight probe endpoints to decide whether the process is up and ready for traffic. You, the operator, check whether each configured LLM can actually serve requests. This page covers both.
Probe endpoints
These endpoints answer "is the gateway process up and able to serve traffic?" without making any LLM calls. They are the canonical liveness and readiness contract for the proxy.
| Endpoint | Auth | Returns | Meaning |
|---|---|---|---|
GET /health/liveliness | none | "I'm alive!" (200), or {"status": "shutting_down"} (503) during graceful shutdown | The process is up. No dependencies are checked. GET /health/liveness is an alias with the Kubernetes spelling; both are real routes |
GET /health/readiness | none | {"status": "healthy", "db": ...} (200) when ready; 503 when a configured database is unreachable | The worker is ready to accept traffic. The db field is "connected", "disconnected", or "Not connected" when no database is configured |
The db value lets an orchestrator distinguish a healthy worker from one that booted but cannot reach its database. When the database is configured and unreachable, readiness returns 503 so the pod is pulled from rotation.
The default readiness payload is deliberately low-detail so it is safe to expose to unauthenticated probes. For full diagnostics (callbacks, cache, version), either set general_settings.allow_public_health_readiness_details: true to expand /health/readiness itself, or call the authenticated GET /health/readiness/details endpoint.
A minimal Kubernetes probe pair on the proxy's port 4000:
livenessProbe:
httpGet:
path: /health/liveliness
port: 4000
readinessProbe:
httpGet:
path: /health/readiness
port: 4000
For full deployment manifests, see the Production Deployment guide and the production checklist.
Model health in the Admin UI
The primary way to check whether your models are serving is the Admin UI. Go to Models + Endpoints, open the Health Status tab, and click Run All Checks. Each model shows a status, error details when it fails, and the last check and last success times.
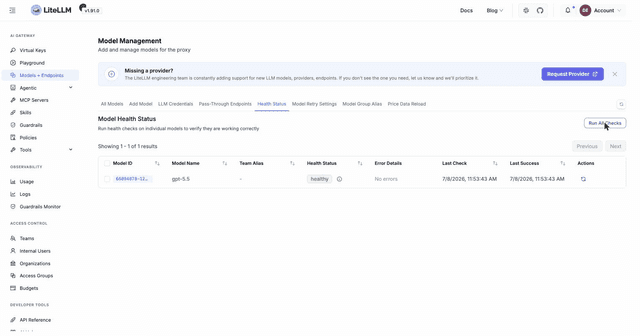
The API equivalent is GET /health, which accepts any valid key. It runs a real test request against every configured model, so it costs a few tokens per model.
curl --location 'http://0.0.0.0:4000/health' -H "Authorization: Bearer sk-1234"
{
"healthy_endpoints": [
{"model": "azure/gpt-35-turbo", "api_base": "https://my-endpoint-canada-berri992.openai.azure.com/"}
],
"unhealthy_endpoints": [
{"model": "azure/gpt-35-turbo", "api_base": "https://openai-france-1234.openai.azure.com/"}
]
}
To check a single model, pass ?model=<model_name> or ?model_id=<id>; you can find a model's id from GET /v1/model/info.
Background health checks
By default /health probes every model on each call. To avoid querying models too frequently, run the checks in the background and have /health serve the last cached result. Configure this in general_settings:
general_settings:
background_health_checks: true # run checks in the background
health_check_interval: 300 # seconds between runs (default 300)
health_check_details: true # include endpoint URLs and errors in the response (default true)
Set health_check_details: false to strip endpoint URLs, error messages, and other params from the response when the proxy is exposed to a broad audience.
To exclude a model from the background loop, set disable_background_health_check: true in its model_info. That only skips the background loop; an on-demand GET /health still probes it unless you also set general_settings.health_check_skip_disabled_background_models: true, which omits those deployments from on-demand and shared health checks as well.
model_list:
- model_name: openai/gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_API_KEY
model_info:
disable_background_health_check: true
For coordinating checks across multiple pods so expensive models are not probed once per pod, see Shared Health Check State.
Model modes
The health check picks the operation to test from the model's model_info.mode. Set it so the probe uses the right API surface; if you leave it unset, LiteLLM auto-detects from the model's capabilities and falls back to a chat completion.
mode | Health check calls |
|---|---|
chat (default) | /chat/completions |
completion | /completions |
embedding | /embeddings |
image_generation | image generation |
audio_transcription | audio transcription |
audio_speech | text to speech (requires health_check_voice) |
rerank | rerank |
batch | batch (Azure only) |
realtime | realtime session |
ocr | OCR |
video_generation | video generation |
For a wildcard route (* in litellm_params.model), set health_check_model to the concrete model the probe should call. With mode unset on a wildcard route, max_tokens is left unset on the probe request.
model_list:
- model_name: azure-embedding-model
litellm_params:
model: azure/azure-embedding-model
api_base: os.environ/AZURE_API_BASE
api_key: os.environ/AZURE_API_KEY
api_version: "2023-07-01-preview"
model_info:
mode: embedding
Health check tuning reference
Set these under a model's model_info unless noted otherwise. They control how the probe request is shaped.
| Key | Default | Purpose |
|---|---|---|
health_check_timeout | 60s | Per-model timeout for the probe |
health_check_max_tokens | 16 (unset for wildcard routes) | max_tokens on the probe request |
health_check_max_tokens_reasoning | unset | max_tokens for reasoning models when health_check_max_tokens is not set |
health_check_max_tokens_non_reasoning | unset | max_tokens for non-reasoning models when health_check_max_tokens is not set |
health_check_reasoning_effort | unset | reasoning_effort on the probe (chat, completion, batch, responses modes only) |
health_check_voice | alloy | Voice for audio_speech probes |
health_check_model | unset | Concrete model a wildcard route probes |
disable_background_health_check | false | Skip this model in the background loop |
Reasoning models often need a higher probe max_tokens because providers count reasoning tokens toward the completion budget; the separate reasoning and non-reasoning keys let you raise it without listing every model. Three environment variables set global defaults: DEFAULT_HEALTH_CHECK_PROMPT overrides the default probe prompt ("test from litellm"), BACKGROUND_HEALTH_CHECK_MAX_TOKENS is the global max_tokens fallback, and BACKGROUND_HEALTH_CHECK_MAX_TOKENS_REASONING takes precedence for non-wildcard reasoning models.
To route traffic away from deployments that fail health checks, see Health Check Driven Routing.
Other health endpoints
All of these require a valid key unless noted.
GET /health/services?service=<name>tests a configured alerting or logging service (datadog, slack, langfuse, and so on); accepts any valid keyGET /health/readiness/detailsreturns the authenticated readiness diagnostics (db, cache, callbacks, version)GET /health/historyreturns past health check resultsGET /health/latestreturns the most recent health check resultGET /health/backlogreturns the number of in-flight requests on the workerGET /health/drainstarts a graceful drain for KubernetespreStophooks; disabled by default (404) unlessgeneral_settings.enable_drain_endpoint: true, and gated by theX-Drain-Tokenheader whenDRAIN_ENDPOINT_TOKENis set